编码器和解码器
写完之后发现编码器和解码器这个框架不是很麻烦,就是一种思想,但是要扯上transformer就很麻烦orz。
一句话总结一下:编码器是可变->固定,解码器是固定->可变 encoder-decoder是seq2seq的一种实现,是深度学习中常见的模型框架。 # 定义 Encoder将可变长度的输入序列编码成一个固定长度的向量; Decoder将固定长度的向量解码成一个可变长度的输出序列; Encoder-Decoder阶段的编码与解码的方式可以是CNN、RNN、LSTM、GRU等 (所以encoder和decoder中间的向量长度是固定的,这也是它的一个缺陷) > 为什么是缺陷,长度固定的+缺点体现在哪里
RNN的编码器解码器
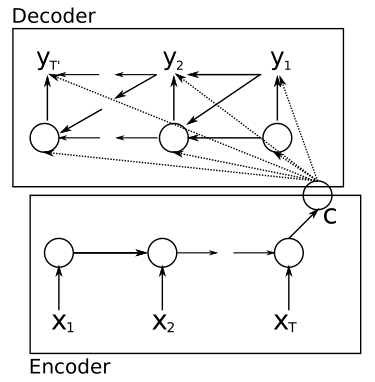 该结构来自论文Learning Phrase Representations
using RNN Encoder–Decoder for Statistical Machine Translation
RNN编码-解码器 ,该模型包含两个RNN,分别位于编码器和解码器中。
编码器中的RNN负责将变长的输入序列映射到一个固定长度的向量中,解码器中的RNN则负责将向量映射到一个变长的输出序列中。
定性的来讲,这个模型可以学习语言短语的有意义的的语义和句法表示。 ###
编码器 编码器部分的隐藏层状态用 \(h_t\)表示,隐含层更新公式为 \[
h_t=f(h_{t-1},x_t)
\]
f是一个函数,可以是简单的sigmoid,也可以是复杂的LSTM,上文提到的论文里面用的是GRU
C
是中间语义表示,可以是h总和也可以是最后一个h,看用的什么方法。这里描述的是用RNN,RNN的信息会流到最后,所以这篇paper里用的是最后一个h
### 解码器 解码器的隐含层更新为 \[
s_t=g(s_{t-1},y_{t-1},c)
\] 最后模型的输出预测为 \[
P(y_t|y_{t-1},y_{t-2},...y_1,c)=g(s_t,y_{t-1},c)
\] ### 训练 对解码阶段每个时间步骤i,解码器输出\(y_i\)的条件概率为\(P(y_i|y_1...y_{i-1},c)\),输出序列的联合概率函数为
\[
P(y_1,...y_{T'}|x_1,...x_T)=\prod_{i=1}^{T'}P(y_i|y_1...y_{i-1},c)
\]
该结构来自论文Learning Phrase Representations
using RNN Encoder–Decoder for Statistical Machine Translation
RNN编码-解码器 ,该模型包含两个RNN,分别位于编码器和解码器中。
编码器中的RNN负责将变长的输入序列映射到一个固定长度的向量中,解码器中的RNN则负责将向量映射到一个变长的输出序列中。
定性的来讲,这个模型可以学习语言短语的有意义的的语义和句法表示。 ###
编码器 编码器部分的隐藏层状态用 \(h_t\)表示,隐含层更新公式为 \[
h_t=f(h_{t-1},x_t)
\]
f是一个函数,可以是简单的sigmoid,也可以是复杂的LSTM,上文提到的论文里面用的是GRU
C
是中间语义表示,可以是h总和也可以是最后一个h,看用的什么方法。这里描述的是用RNN,RNN的信息会流到最后,所以这篇paper里用的是最后一个h
### 解码器 解码器的隐含层更新为 \[
s_t=g(s_{t-1},y_{t-1},c)
\] 最后模型的输出预测为 \[
P(y_t|y_{t-1},y_{t-2},...y_1,c)=g(s_t,y_{t-1},c)
\] ### 训练 对解码阶段每个时间步骤i,解码器输出\(y_i\)的条件概率为\(P(y_i|y_1...y_{i-1},c)\),输出序列的联合概率函数为
\[
P(y_1,...y_{T'}|x_1,...x_T)=\prod_{i=1}^{T'}P(y_i|y_1...y_{i-1},c)
\]
想要最大化输出序列的联合概率,根据最大似然估计
\[ max_\theta \frac{1}{N} \sum_{n=1}^N logp_\theta(y_n|x_n) \]
引入注意力
在普通的编码器-解码器模型中,有一个很大的局限性。那就是上下文变量对于 Decoding 阶段每个时间步都是一样的,这可能是模型性能的一个瓶颈。
我们希望不同时间步的解码能够依赖于与之更相关的上下文信息,换句话说,Decoding 往往并不需要整个输入序列的信息,而是要有所侧重。于是,Bengio 团队的 Bahdanau 在 2014年首次在编码器-解码器模型中引入了注意力机制 (Attention Mechanism)
具体做法: 在解码器过程中,在时间步i,将c泛化为\(c_i\) 注意力机制的目标是让解码器在每一时间步对输入序列中不同时间步编码的信息分配不同的注意力。那么体现在上下文变量中, \(c_i\)就是 Encoder 中不同时间步的隐藏状态的加权平均。
编码器在时间步骤t的隐藏状态为\(h_t\),总时间步数为T。解码器在时间步i的上下文变量c变为 \[ c_i=\sum_{t=1}^T\alpha_{it}h_t \] 其中alpha是权重,也就是说,给定解码器的当前时间步i,我们需要对编码器中不同时间步t的隐藏状态求加权平均。说到加权平均,我们很容易想到 softmax 函数。这里的权值也称注意力权重。它的计算公式是 \[ \alpha_{it}=\frac{exp(e_{it})}{\sum_{k=1}^Texp(e_{ik})} \] 其中 \[ e_{it}=attention(s_{i-1},h_t) \] attention就是注意力函数