TinyLLM: Learning a Small Student from Multiple Large Language Models
小样本llm论文阅读,百篇paper计划(3/100)
要看小样本了,随便找了一篇比较新的,不好看不要怪我。
- 论文标题:TinyLLM: Learning a Small Student from Multiple Large Language Models
- arxiv地址:链接
- code:
abstract
- 问题:将推理能力从较强的大语言模型转移到较小的llms上面
- 目前:知识蒸馏knowledge distillation,其优点是突出的高效性和泛化性,缺点是知识多样性有限、缺乏丰富的上下文信息。
- 要解决:解决以上提到的知识蒸馏的bug,促进紧凑语言模型(compact language model)的学习
- 提出:TINYLLM,是一种知识蒸馏范式,从多个大的教师llm中学习一个小的学生llm
- 具体来说:鼓励学生llm不仅能够生成正确的答案,还要理解答案背后的理论基础;鉴于不同的LLMs具有不同的推理能力,我们引导学生模型从不同的教师LLMs中同化知识。
- 其他贡献:进一步引入了一个语境范例生成器(in-context example generator)和一个教师驱动的思维链(chain of thought)策略,以确保理论基础的准确性和在适当的情景中的基础。
- 实验与结果:在两个推理任务的6个数据集上的大量实验证明了本文方法的优越性。实验结果表明,尽管TinyLLM的模型尺寸较小,但其性能明显优于大型教师LLM。
看第一遍之后的想法:
有几个术语不知道:知识蒸馏、紧凑语言模型、教师llm和学生llm是怎么运行的、预警范例生成器、思维链。
它这个是根据任务做的,还是可以推广到所有模型上?
introduction
问题从何来
问题就是大模型好,小模型不行。知识蒸馏是缓解较大模型和较小模型之间性能差距的工具。
但是知识蒸馏有俩问题:
有限的知识多样性:
目前的研究主要采用单一教师的方法,将学生模型的学习范围限制在其自身训练和结构设计中得到的知识。这意味着学生模型仅限于教师的观点、偏见和潜在弱点。
缺乏丰富的情境信息:
虽然理论在有效推理中起重要作用,但目前的研究主要集中在利用真值标签,这些标签表明了正确的答案,但并没有提供关于答案背后的推理和思维过程的见解。
tinyllm是什么
针对上述问题,提出TINYLLM,即一个通过对多个大的教师LLM在理论指导下提取知识,从而提高小的学生LLM推理能力的范式。
注:TINYLLM是一种diagram范式 范式是什么?
tinyllm怎么做的+功能
具体来说:TinyLLM通过引入多个教师模型作为共同顾问(co-advisors)来缓解有限的知识多样性问题。为了充分利用每个教师模型,缓解缺乏丰富上下文信息的问题,TinyLLM要求教师提供合理的理由来支持答案。通过向多位教师学习,学生模型可以继承更广泛的技能和知识,从而获得更好的泛化能力。
此外,为了确保理论基础建立在情境适当的场景中,并反映真实的底层推理过程,TinyLLM具有语境示例生成器和教师强制的思维链策略,使教师通过演示理解任务并生成准确的理论基础。
评估与结果
为了全面评估我们的方法,我们在常识和生物医学推理任务的6个数据集上进行了实验。
结果表明,与完全微调(full fine-tuning)相比,使用我们的范式可以提高xx性能,并且模型尺寸明显较小。我们还进行了消融研究,以证明教师理论的有效性,并进行了超参数分析,以进行综合评估。
主要贡献
不用管orz
- 我们发现现有学习较小语言模型的工作存在两个问题:1 )知识多样性有限;2 )缺乏丰富的上下文信息。
- 为了解决这些问题,我们提出了一种新的知识蒸馏范式TinyLLM,通过从多个大型教师LLM中迁移推理能力来学习一个小型学生LLM。我们鼓励学生LLM理解生成答案背后的原理。
- 在六个数据集和两个推理任务中,大量实验验证了TinyLLM的优越性。TinyLLM在模型大小为1.1 %的情况下,可以获得高达+ 12.57 %的性能提升。
总结
- 背景:要搞小模型,就要知识蒸馏,知识蒸馏有俩问题
- 解决:提出llm
- 是什么:一个范式,学习多个教师+理论指导
- 咋做的:多个教师作为co-advisors,要求教师提供理由
- 额外的:语境示例生成器+教师强制的思维链
method
tinyllm的流程图 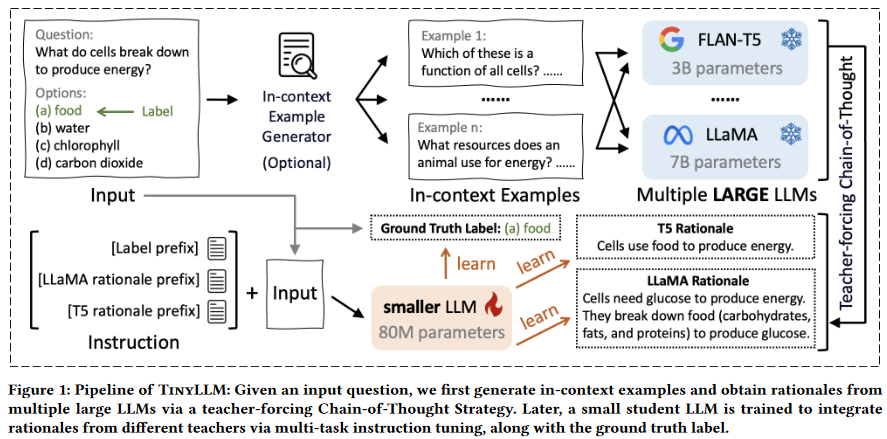
给定一个输入问题,我们首先生成语境例子,并通过教师驱动的思维链策略从多个大型LLM中获得理论基础。之后,一个小型的学生LLM被训练通过多任务指导调整来整合来自不同教师的理论基础,以及基本真值标签。
预备知识
多选答题
k-way多选问题回答(MCQA)定义:
给定一个问题Qi,一个候选答案选项集Oi = { Oi1,Oi2,..,Oik },模型的任务是从集合Oi中选择正确的答案,使得所选答案与真实答案标签Ai对齐。
知识蒸馏
知识蒸馏过程从教师模型开始,用θT参数化的T表示,该模型已经在大型语料库上进行了预训练。之后,带有参数θS的学生模型S要完成利用T的强大能力直接从T中提取知识的任务。
从教师那里获取理论基础
语境实例生成器
为了使教师生成的理据能够扎根于情境适宜的场景中,我们引入了一个可选的语境实例生成器。该工具为任意给定的输入生成语境示例,提供关于输入数据和任务的更多详细信息。
为简单起见,我们在同一数据集中随机选取例子。这有助于教师LLMs更深入地理解任务的性质和特点。通过集成该生成器,我们促进了教师模型更明智和细致入微地生成理论基础,增强了学生模型的学习体验。
教师强制思维链
用教师强迫策略来确保理论基础的有效性。
与现有方法【简单地使用规则思维链(CoT)机制),其中LLM由问题集和选项集{Qi,Oi}提示以直接获得理据Ri】相比,TinyLLM在将正确答案Ai整合到输入中方面具有明显的优势。
我们假设是因为:Ai与Qi和Oi放一起有助于对输入语境和导致答案的正确逻辑理据进行更细致入微的理解,从而促进更明智和准确的生成过程。
具体来说,我们考虑问题、选项和答案的串联{ Qi,Oi,Ai }作为LLMs的输入。
多位教师的理论
给定M个教师,TinyLLM开创性地使用了多教师架构,其中每个教师Tm是一个LLM。特别地,利用问题Qi、选项Oi、正确答案Ai和语境示例Pi推导出特定教师模型θ Tm对第i个问题产生的理据R^m_i。该过程形式化为: \[ R_i^m=T^m(Q_i,O_i,A_i,P_i;\theta_{T^m}) \]
学习一个小的学生模型
将理论知识作为监督的直接策略是将教师模型产生的每个理据\(R_i^m\)与问题Qi和选项Oi一起作为学生模型的补充输入。然而,该方法在推理阶段由于计算资源的限制而面临挑战,特别是因为训练集和测试集中的每个数据样本都必须预先生成理论基础。
为了克服这个问题,我们在训练过程中使用理论知识作为监督信号的一种形式,以开发一个善于生成自己解释的模型。随后,这个训练好的模型可以在测试集上使用,不需要预先生成合理的论据,以促进准确的推理。
哪里不需要预先生成论据R了?是测试集上不用生成吗
具体来说,TinyLLM将来自多个教师模型的理论整合到一个统一的多任务教学调优框架中。这就需要分配一个唯一的前缀p来区分来自不同教师的学习任务。学生模型不仅需要被训用于预测标签,还要生成和教师差不多的论据。总体的损失函数L: \[ L=L_A+\sum_{m=1}^M \alpha ^m L_{T^m} \] LA表示向真实答案学习的目标,LTm表示向第m个教师学习的目标,αm为Tm的重要性权重,M为教师LLM的数量。形式上,LA和LTm定义如下: \[ L_A=\frac{1}{N}\sum_{i=1}^N l(S(Q_i,O_i,P_A;\theta _S),A_i)\\\\ L_{T_m}=\frac{1}{N}l(S(Q_i,O_i,p_m;\theta _S),R_i^m) \]
N是数据集的个数,l表示预测令牌和目标令牌之间的交叉熵损失cross-entropy loss。LA鼓励学生S在给定问题Qi、选项Oi和生成答案的指令前缀pA的情况下,通过最小化它与学生输出之间的差异来生成真值答案Ai。
“它”指代LA产生的输出
另一方面,\(L^m_T\)通过学习教师Tm的推理理据\(R^m_i\),以Tm的指令前缀pm为指导,促进学生S模仿Tm的推理能力。
总结
- 预备知识
- 多选QCMA
- 知识蒸馏:教师和学生模型
- 从教师获得理论
- 语境实例生成器:为任意给定的输入生成语境示例
- 教师强制思维链:问题、选项和答案的串联作为llms的输入
- 从多个教师学习理论
- 学生模型的学习方式
- 学习答案LA
- 学习结束LTm
实验
实验设置
数据集
我们遵循GNP中的设置来使用常识推理和生物医学推理数据集,包括OpenBookQA ( OBQA ),AI2推理挑战( ARC ) ,物理交互问答( PIQA ) ,RiddleSense ( Riddle ),PubMedQA ( PQA ) 和BioASQ。
基准baseline
我们将TinyLLM与教师的表现和各种训练方法进行了比较,包括没有训练的inference配置,更新参数子集的高效训练方法LoRA,以及更新学生所有参数的全微调。
实现细节
对于TinyLLM,设置学习率为\(5\times 10^{-5}\),批大小为16,最大输入长度为1024,epoch为1。
权衡权重\(\alpha_{T_n}\)在{ 0.01,0.1,0.5,1,2,3 }内取值。
对于LLMs的选择,我们使用FLAN - T5 small ( 80M ),base ( 250M ),and large ( 780M )作为学生,FLAN-T5 xlarge ( 3B )和LLaMA 2-chat ( 7B )作为教师。
实验在4个NVIDIA Tesla H100 GPU上进行。
结果比较
与学生学习方法的比较
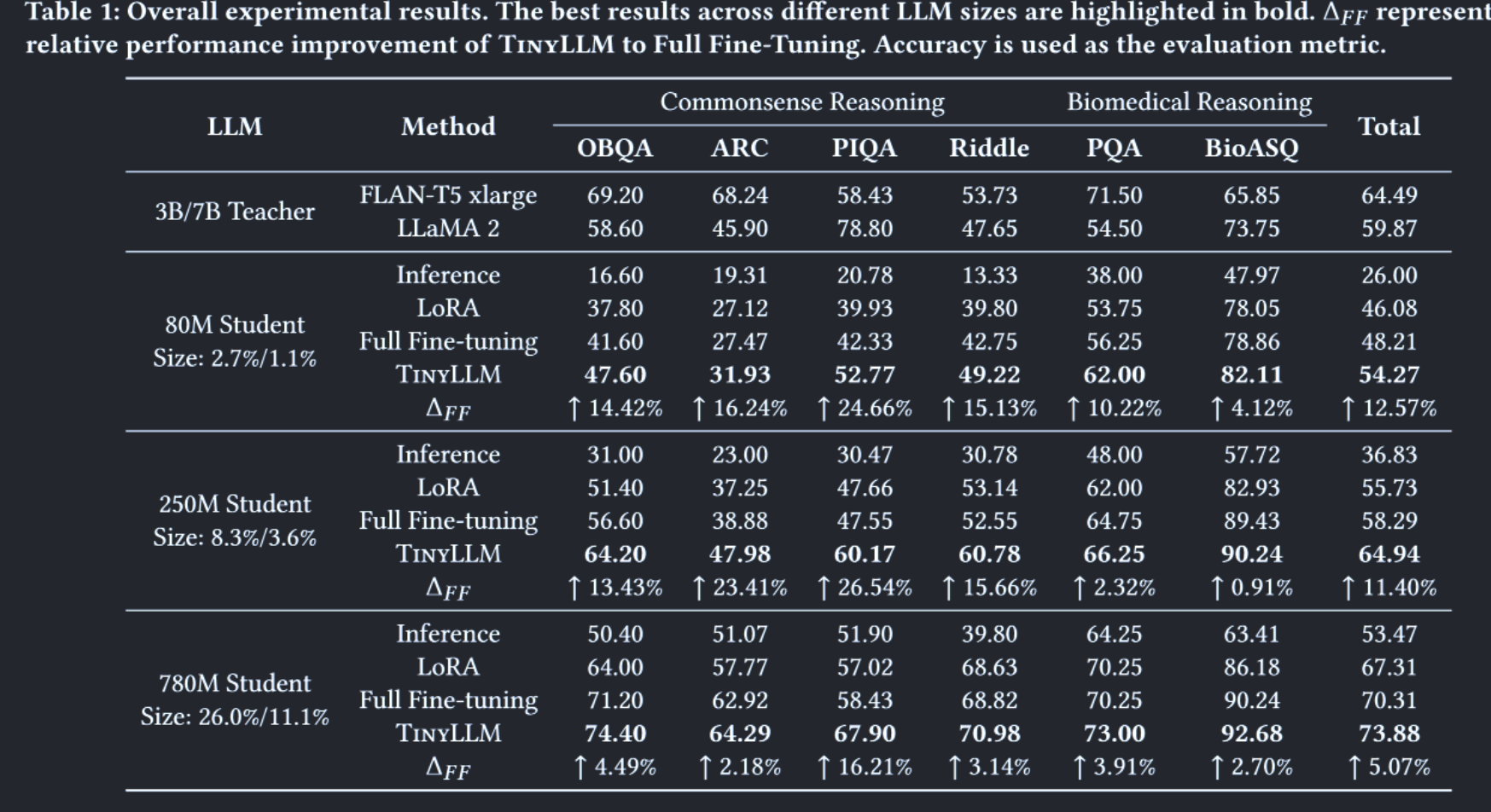
六个数据集和两个推理任务的结果如表1所示。从表中,我们观察到采用全微调方法,尽管其理论上增强了参数调整的能力,但并不总是产生优于LoRA的结果。相反,TinyLLM在所有数据集和LLM大小上都表现出显著的性能增强。
总体而言,TinyLLM在参数为80M、250M和780M的学生中平均提升了+ 12.57 %、+ 11.40 %和+ 5.07 %。这验证了TinyLLM的有效性,强调了向教师学习的重要性和好处。
和教师模型比较
与教师模型相比,TinyLLM也表现出更优越的性能。例如,一个780M的学生在不同的数据集上可以达到73.88的平均性能,比3B教师提高了+ 14.56 %,比7B教师提高了+ 23.40 %。此外,具有250M参数的更小的学生模型可以超越教师( + 0.70%在3B , + 16.82%在7B),而只使用了8.3 %和3.6 %的教师参数。
消融实验
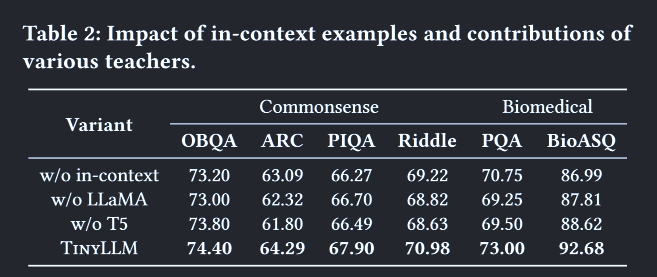
为了进行全面的评估,我们进行了消融研究,以验证语境范例生成器的贡献和来自多位教师的理论基础。为了方便起见,我们创建了TinyLLM的三个消融变体。
- W / o in-contect:排除了理据生成过程中的语境实例。
- w / o LLaMa和 w / o T5排除了蒸馏过程中相应教师模型对理据的监督。
表2描述了完整的TinyLLM模型和它在六个数据集上的消融之间的比较。从表中可以看出,删除语境中的例子和教师理据的成绩下降,说明了它们对模型的提升是有效的。通过组合所有的设计,所提出的TinyLLM达到了最好的性能。这些发现表明,从多位教师那里学习高质量的理性信号,有利于提取具有较好推理能力的小LLM。
参数灵敏度
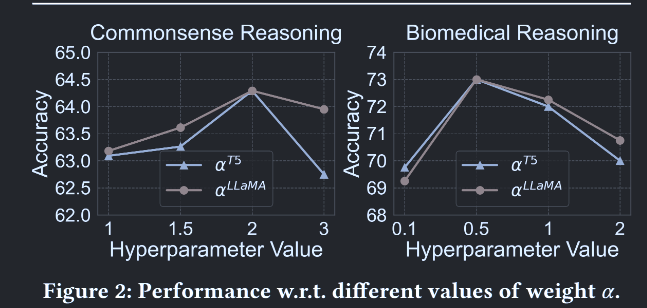
权衡权重(trade-off weights,也就是公式中的\(\alpha_{T_n}\))的探索揭示了模型对不同参数值选择的适应性。我们在图2中的常识推理数据集ARC和生物医学推理数据集PQA上进行了敏感性实验。从图中可以看出,不同数据集和任务的最优参数不同。造成这种现象的原因是生物医学推理问题往往冗长复杂,弱化了教师理据性的影响,使得较小的α值就足够了。相比之下,常识推理问题通常简洁明了,使得来自教师模型的理论基础具有价值,并导致α的大量值。
总结
- 实验设置
- 结果
- tinyllm和其他方法
- tinyllm和教师llm
- 消融实验证明有效性
总结
在本文中,我们提出了TinyLLM,一种新颖的知识蒸馏范式,从多个大的教师LLM中学习一个小的学生LLM。TinyLLM涉及多个创新设计,例如在不同教师之间继承更广泛的知识,并使用语境示例生成器和教师驱动的思维链策略学习上下文相关的、准确的原理。在六个数据集和两个推理任务上的大量实验验证了TinyLLM的优越性。
未竟之事:
- 教师-学生模型怎么运作的
- 思维链是什么