Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
思维链论文阅读,百篇paper计划(4/100),思维链这个技术还是prompt这个部分里面的,所以这篇论文还是算prompt - 论文标题:Chain-of-Thought Prompting Elicits Reasoning in Large Language Models - 地址:arxiv
虽然这篇优点早了(2022年),但是毕竟是提出思维链这个方法的,看起来不会差xD吧?。
真实情况是我看完之后也不知道思维链算不算算法,是人工添加的?
abstrac
如何生成一条思维链:一系列中间推理步骤,可以显著提高大型语言模型执行复杂推理的能力。特别地,我们通过一个叫做思想链提示的简单方法展示了这种推理能力如何在足够大的语言模型中自然地涌现出来,其中提供了一些思想链示范作为提示的范例。
在三个大型语言模型上的实验表明,在一系列算术、常识和符号推理任务上,思维链提示提高了性能。经验上的收益可能是惊人的。例如,仅用8个思维链示例就提示一个PaLM 540B,在数学应用题的GSM8K基准上达到了最先进的精度,甚至超过了用验证器微调的GPT-3。
introduction
工作总结
本工作探讨了如何通过一种简单的方法来解锁大型语言模型的推理能力
背景
自然语言
算术推理技术可以从生成最终答案的自然语言理据中获益。、
先前的工作已经赋予模型通过从头训练(scratch)或微调预训练模型(finetune)来生成自然语言中间步骤的能力,除了使用形式语言代替自然语言的神经符号方法(necro-symbolic)外。
大语言模型
大型语言模型提供了在语境中通过提示(prompt)进行少量学习的令人兴奋的前景。
也就是说,不是为每个新任务微调一个单独的语言模型检查点,而是简单地用几个输入-输出示例来"提示"模型。值得注意的是,这对于一系列简单的问答任务来说是成功的。
缺点
对于理据增强的训练和微调方法,创建大量高质量的理据集是非常昂贵的,这比普通机器学习中使用的简单输入输出对要复杂得多。
对于传统的小样本提示方法,它在需要推理能力的任务上效果不佳,并且往往随着语言模型规模的增加而没有实质性的提高。
贡献
在本文中,我们以避免其局限性的方式结合了这两种思想的优点。
具体来说,给定一个由三元组〈输入,思维链,输出〉组成的提示,我们探讨语言模型对推理任务进行小样本提示的能力。思维链是导致最终输出的一系列中间自然语言推理步骤,我们将这种方式称为思维链提示。
实验结果
我们对算术、常识和符号推理基准进行了实证评估,结果表明,思维链提示优于标准提示,有时甚至达到惊人的程度。
在数学应用题的GSM8K测试集上,使用PaLM 540B的思维链提示大大优于标准提示,取得了新的性能。一个只有提示的方法很重要,因为它不需要大型的训练数据集,而且单个模型检查点可以执行许多任务而不失一般性。
这项工作强调了大型语言模型如何通过几个例子来学习任务的自然语言数据(也就是通过一个大型的训练数据集自动学习输入和输出的模式)。
chain-of-thought prompting
当在解决一个复杂的推理任务(如多步数学应用题)时考虑自己的思维过程:在给出最终答案之前,将问题分解成中间步骤并逐一解决是典型的做法:"简给妈妈2朵花后,她有10朵.. ..然后给爸爸3朵花后,她有7朵.. ..所以答案是7 "。
本文的目标是赋予语言模型生成类似思想链的能力——一系列连贯的中间推理步骤,从而得出问题的最终答案。我们将证明,足够大的语言模型可以产生思维链,如果在示例中提供思维链推理的演示,以进行少量的提示。
作为一种促进语言模型中推理的方法,思想链提示具有几个吸引人的特性。
- 原则上,链式思维允许模型将多步问题分解为中间步骤,这意味着额外的计算可以分配给需要更多推理步骤的问题。
- 思想链为模型的行为提供了一个可解释的窗口,表明它怎样到达特定的答案,并提供机会去调试推理路径出错的地方(尽管完全刻画一个模型支持一个答案的计算仍然是一个开放的问题)。
- 思维链推理可以用于数学应用题、常识推理和符号操作等任务,并且对任何人类可以通过语言解决的任务都具有潜在的适用性。
- 在足够大的现成语言模型中,只需将思维链序列的例子放入少量提示的例子中,就可以很容易地引出思维链推理。
在实证实验中,我们将观察思维链提示对算术推理(第3节)、常识推理(第4节)和符号推理(第5节)的效用。
真的能debug?通过cot
算术推理
首先考虑数学应用题,它衡量语言模型的算术推理能力。虽然对于人类来说很简单,但是算术推理是语言模型经常要面对的任务。令人惊讶的是,当与540B参数语言模型一起使用时,链式提示在多个任务上表现出与特定任务微调模型相当的性能,甚至在具有挑战性的GSM8K基准程序(GSM8K benchmark)上达到了新的水平。
实验设置
在多个基准上探索了不同语言模型的思维链提示
基准
考虑以下五个数学应用题基准:( 1 )数学应用题GSM8K基准题,( 2 )变结构数学应用题SVAMP数据集,( 3 )不同类型数学应用题ASDiv数据集,( 4 )代数应用题AQuA数据集,( 5 ) MAWPS基准题。
标准提示
对于baseline,我们考虑标准的小样本提示(few-shot prompt),其中一个语言模型在输出一个测试时间示例的预测之前给出了输入-输出对的语境范例。示例被格式化为问题和答案。模型直接给出答案。
cot提示
在少量提示的情况下,对每个样例进行扩充,并给出一个关联答案的思路链。由于大部分数据集只有一个评价拆分,作者手工合成了一组8个带有提示思路链的小样本示例。(这些特殊的例子没有经过prompt工程,健壮性研究在后面)
为了调查这种形式的思维链提示是否能成功地引发跨越一系列数学问题的成功推理,我们对除AQuA之外的所有基准都使用了这套单套8条思维链示例,这是多重选择而不是自由反应。对于AQuA,我们使用了来自训练集的四个示例和解决方案。
语言模型
我们评估了五个大型语言模型。
- 第一种是GPT-3,我们使用text-ada-001, text-babbage-001, text-curie-001, and text-davinci-002,这可能对应于InstructGPT模型的350M,1.3B,6.7B和175B参数。
- 第二个是La MDA,它有422M、2B、8B、68B和137B参数的模型。
- 第三种是PaLM,它有8B,62B和540B参数的模型。
- 第四种是UL2 20B
- 第五种是Codex
我们通过贪婪解码greedy decoding(尽管后续工作表明,通过在许多抽样世代中采取大多数最终答案,可以改善思维链提示)从模型中采样。对于LaMDA,我们报告了5个随机种子的平均结果,其中每个种子具有不同的随机混洗顺序。由于LaMDA实验在不同种子之间没有表现出较大的差异,为了节省计算,我们报告了所有其他模型的单个样本顺序的结果。
结果
图表
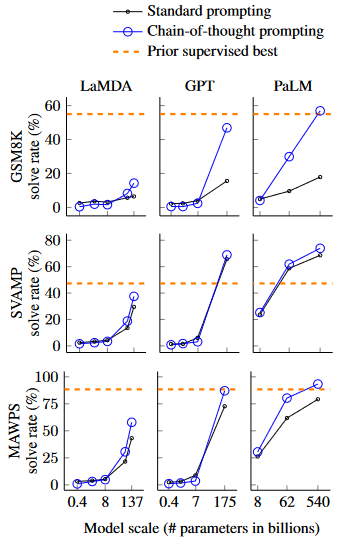
这个图这里横纵坐标都什么意思?
- 每个表格的横坐标是模型的参数量(在上一节实验设置里面提到的三种模型规模,稍微近似了一下)
- 每个表格的纵坐标问题的解决率(可以理解成模型的准确率)
- 整个大图的横坐标是三个模型:LaMDA|GPT|PaLM(实验不是设置了5个嘛,选了前三个,后面两个都在俘虏里面说明,看这三个也够了)
- 整个大图的纵坐标的3个基准/数据集:GSM8K|SVAMP|MAWPS(同样的,当时也写了5个,但是只选了三个)
- 比较的是标准prompt和chain-of-thought的方法所产生的问题解决率在不同模型和不同参数量下的差别
分析图表
- 首先,图4显示,思维链提示是模型尺度的涌现能力。也就是说,对于较小的模型,意念链提示并不会对性能产生积极的影响,只有当与参数为~100B的模型一起使用时,才会产生性能增益。我们定性地发现,较小规模的模型产生了流畅但不合逻辑的思维链,导致了比标准提示更低的性能。
- 第二,对于更复杂的问题,思维链提示具有更大的绩效增益。例如,对于GSM8K (基线性能最低的数据集),最大的GPT和PaLM模型的性能提高了一倍以上。另一方面,对于MAWPS最简单的子集SingleOp (仅需一个步骤即可解决),性能改进要么是负面的,要么是很小的(附录中的内容)。
- 第三,通过GPT - 3 175B和PaLM 540B的思想链提示优于现有技术,也就是通常在标记的训练数据集上微调特定任务的模型这种做法。图4展示了PaLM 540B在GSM8K、SVAMP和MAWPS (尽管注意到标准提示已经通过了SVAMP的最佳标准)上如何利用链式提示实现新的技术状态。在另外两个数据集AQuA和ASDiv上,有思维链提示的PaLM达到了最先进的状态的2%以内(附录)。
原因
为了更好地理解"思维链提示"起作用的原因,我们手工检查了LaMDA 137B为GSM8K生成的模型。在模型返回正确最终答案的50个随机例子中,除了2个巧合地得到正确答案(正确的模型生成思想链的例子见附录D.1和表8)之外,所有生成的思维链在逻辑上和数学上都是正确的。我们还随机考察了模型给出错误答案的50个随机样本。这一分析的总结是,除小错误(计算器错误、符号映射错误或一个推理步骤缺失)外,46 %的思维链几乎正确,其余54 %的思维链在语义理解或连贯性方面存在大错误(见附录D。2)。为了提供一个小的洞察为什么缩放提高了链式推理能力,我们对PaLM 62B的错误进行了类似的分析,并分析了这些错误是否通过缩放到PaLM 540B中得到了修正。总结起来,将PaLM缩放到540B修正了62B模型(见附录A.1)中一步法缺失和语义理解错误的很大一部分。
这部分没看懂
消融实验
因为思想链提示好,产生了一个新问题,即是否可以通过其他类型的提示来赋予相同的性能改进。图5显示了下面描述的三种不同思路的消融研究。
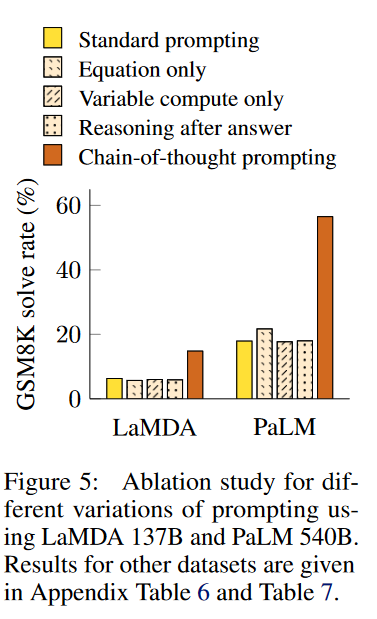
只有方程
思维链提示可能有帮助的一个原因是它产生了待评估的数学方程,因此我们测试了一个变式,即在给出答案之前,提示模型只输出一个数学方程。图5显示,仅有提示的公式对于GSM8K来说帮助不大,这暗示了GSM8K中问题的语义太具有挑战性,无法直接转化为公式,而不需要思路链中的自然语言推理步骤。
然而,对于一步法或两步法问题(one-step or two-step problems)的数据集,我们发现只提示方程确实可以提高性能,因为方程可以很容易地从问题(见附录)推导出来。
只有变量计算
另一个直觉是,思维链允许模型在更难的问题上花费更多的计算(即中间token)。为了将变量计算的影响从思维链推理中分离出来,我们测试了一个配置,在这个配置中,模型被提示输出一个仅有的点序列(...),等于解决问题所需的方程中的字符数。这个变体的表现与基线大致相同,这表明变量计算本身不是思想链提示成功的原因,并且通过自然语言表达中间步骤似乎有效用。
回答之后的思路链
思维链提示的另一个潜在好处可能是,这种提示可以让模型更好地获取预训练过程中获得的相关知识。因此,我们测试了一个备选配置,其中思想链提示仅在答案后给出,隔离了模型是否实际依赖于产生的思想链给出最终答案。这个变体的表现与基线大致相同,这表明思想链中体现的顺序推理对于不仅仅是激活知识的原因是有用的。
健壮性
对样例的敏感性是提示方法的一个重要考虑因素。例如,改变少样本样例的排列可以使GPT - 3在SST - 2上的准确率从接近概率chance?( 54.3 % )到近最新研究(93.4%)。
在这个最后的小节中,我们评估不同注释器(annotators)编写的思想链的健壮性。
annotator到底是什么?
这部分我看不清晰,涉及到附录的部分太多了,总结一下作者通过一些不同的注释进行消融实验,最终得到的结论是:所有的思维链提示都大大超过了标准基线。
从而得到:思维链的成功使用并不依赖于特定的语言风格。
常识推理
基准benchmark
5个数据集
- 流行的CSQA ( Talmor等, 2019)提出关于世界的常识性问题,涉及复杂的语义,往往需要先验知识。
- StrategyQA ( Geva et al , 2021)需要模型推断多跳策略来回答问题。
- 我们从BIG-bench effort( BIG-bench协作, 2021)中选择了两个专门的评价集:"Date understanding"和"Sports understanding",前者涉及从给定的上下文中推断一个日期,后者涉及确定一个与体育有关的句子是否合理。
- 最后,Say Can数据集( Ahn et al , 2022)涉及将自然语言指令从离散集合映射到机器人动作序列。
提示prompt
我们遵循与上一部分相同的实验设置。对于CSQA和StrategyQA,我们从训练集中随机选择示例,并为它们手工组成思路链,以使用少量示例。两个BIG -bench任务没有训练集,因此我们选择前十个示例作为评估集中的示例,作为少样本示例,并在剩余的评估集中报告编号。对于SayCan,我们使用了Ahn等人( 2022 )中使用的训练集的六个例子,并手工组成了思维链。
结果
结果懒得再截图了,直接结论:在需要一系列常识推理能力的任务(虽然注意到在CSQA上增益是最小的)上,思维链提示也能提高绩效。
符号推理
任务
- 最后一个字母串联:该任务要求模型将单词的最后一个字母串联成一个名为(例如, ' Amy Brown '→' yn ')的单词。这是一个更具挑战性的首字母串接版本,语言模型已经可以在没有思想链的情况下执行。3我们通过从姓名普查数据( https://namecensus.com/).中随机串接前一千个名字和姓生成全名。
- 硬币翻转。该任务要求模型回答人们翻动或不翻动硬币后,硬币朝上还是朝下。菲比翻转硬币。奥斯瓦尔多不抛硬币。硬币还在头上吗? '→'不'
结果
省流:都解决了,但是小样本上还是不行。
对于OOD评估,两种任务的标准提示都失败了。通过思想链的提示,语言模型实现了向上缩放曲线(尽管性能低于域内设置)。因此,对于足够规模的语言模型,思想链的提示促进了超出所见思想链的长度泛化。
讨论
总结上面实验干了啥
我们探索了思维链提示作为一种简单的机制,用于在大型语言模型中诱导多步推理行为。
我们首先看到,在算术推理方面,思维链的提示大大地提高了性能,产生了比消融更强大的改进,并对不同的注释器、范例和语言模型具有鲁棒性。关于常识推理的实验强调了思维链推理的语言学性质如何使其普遍适用。最后,我们证明了对于符号推理,思想链提示有助于OOD泛化到更长的序列长度。在所有的实验中,通过提示一个现成的语言模型来简单地引出思维链推理。在本文的写作过程中没有对语言模型进行微调。
展望
作为模型规模结果的思想链推理的出现一直是流行的主题。对于许多标准提示具有平坦缩放曲线的推理任务,思想链提示导致缩放曲线急剧增加。思想链提示似乎扩展了大型语言模型能够成功执行的任务集——换句话说,我们的工作强调标准提示只提供了大型语言模型能力的一个下界。这种观察可能会提出比它所回答的更多的问题——比如,随着模型规模的进一步增加,我们还能期望推理能力提高多少?其他的提示方法可能会扩大语言模型所能解决的任务范围?
局限
至于局限性,我们首先限定,虽然思维链模仿了人类推理者的思维过程,但这并不能回答神经网络是否真的是"推理",我们将其作为一个开放性问题留下。其次,尽管在小样本的情况下,人工增加带有思维链的样本的成本是最小的,但是这种注释成本对于微调(虽然这可以通过合成数据生成或零样本泛化来克服)来说可能是高昂的。第三,没有正确推理路径的保证,既可能导致正确答案,也可能导致错误答案;改进语言模型的事实生成是未来工作的开放方向。最后,仅在大模型规模下的思想链推理的出现使得服务于现实世界的应用代价高昂;进一步的研究可以探索如何在更小的模型中进行推理。
个人理解
思维链
- 思维链是啥?一种prompt
- 长啥样?相当于举一反三,给出推理步骤
- 怎么整出来?思维链的主要思想是通过向大语言模型展示一些少量的 exapmles,在样例中解释推理过程 ## 怎么用的 三元组〈输入,思维链,输出〉组成提示
功能
论文针对了算术、尝试、符号推理三种情况测试了一遍,效果都不错。