FlexGen: high-throughput generative inference of large language models with a single GPU
推理llm里面搞卸载的。百篇阅读计划(5/100)。看到和以前有点相关联的地方了,卸载和内存优化都是偏系统的。
因为大的背景过于重复了,以后论文注解只记录小的背景了。
- 论文标题:FlexGen: high-throughput generative inference of large language models
- arxiv地址:链接
- code:github
- rank: ICML'23: Proceedings of the 40th International Conference on Machine Learning
- 打标签:做llm推理的、
abstract
- 背景:批处理对延迟不敏感任务的新兴需求
- 干了什么:利用有限的资源,如单个商品GPU,展开了对high throughputLLM推断的研究
- 做出来的成果:FlexGen,这是一个用于在GPU内存有限的情况下运行LLM的高吞吐量生成引擎。
- flexgen的特点:通过聚合来自GPU、CPU和磁盘的内存和计算,FlexGen可以在各种硬件资源约束下灵活配置。
- 它的原理:通过求解一个线性规划linear programming问题,它搜索有效的模式来存储和访问张量。FlexGen进一步将权重和注意力缓存压缩到4位精度损失可以忽略不计。这些技术使得FlexGen具有更大的批次大小选择空间,从而显著提高了最大吞吐量。
- 结果:当在单个16GB GPU上运行OPT-175B时,FlexGen获得了显著高于当前最先进的装载系统的吞吐量,首次达到了1 token / s的生成吞吐量,有效批处理大小为144。在HELM基准上,FlexGen可以在21小时内用16GB的GPU在7个具有代表性的子场景上对30B模型进行基准测试。
遗留问题:
- 批处理对延迟不敏感任务 latency-insensitive tasks with batched
processing
- 应该是指一些不需要快速响应的任务
- batched-processing在这里的作用是?因为批处理可以大量工作吗?
- 高通量 high-throughput
- 也可以理解成吞吐量
- 这样任务就可以理解成高吞吐量+高延迟
- 商品级的GPU a single commodity GPU
- 用这个做关键词搜了一下都是论文标题,不知道有哪些GPU
- 这篇论文的实验的硬件条件:
- 24GB RTX 3090 with 125GB CPU Memory and 1TB SSD
- 16GB T4 with 208GB CPU Memory and 1.5TB SSD
- 怎样实现的灵活配置?flexble(应该在后面章节中体现)
- HELM benchmark
- HELM:Holistic Evaluation of Language Models
- benchmark:N-COUNT A benchmark is something whose quality or quantity is known and which can therefore be used as a standard with which other things can be compared.
- 一个算法之所以被称为benchmark,是因为它的性能已经被广泛研究,人们对它性能的表现形式、测量方法都非常熟悉,因此可以作为标准方法来衡量其他方法的好坏。
- 压缩到4bit之前的权重和注意缓存是多大?
- offloading system有哪些?(就是同行,我也没找到,过会儿去实验那一章找找)
introduction
前面的工作
- 基础设定:throughputoriented generative inference 面向吞吐量的生成式推理
- 研究思路:一些后台任务需要在大量token上批量进行llm推理,并且对延迟不太敏感。so可以在这些工作负载中权衡延迟以获得更高的吞吐量,从而为减少资源需求提供机会。
- 面向吞吐量的生成式推理先前工作:3种方向
- 模型压缩以减少总的内存占用 model compression;
- 协同推理,通过去中心化来分摊推理成本 collaborative inference;
- 卸载,以从CPU和磁盘中使用内存 offloading
- 先前工作的局限性:
- 前两个方向的研究往往假设模型与GPU内存相契合,从而难以在单一商品GPU上运行175B规模的模型。
- 另一方面,由于I / O调度和张量放置效率低下,第三类现有的基于卸载的系统在单个GPU上无法达到可接受的吞吐量。例如,这些系统可能会被小批量的(例如,在某些情况下, OPT - 175B的批次大小只有一个或两个)难倒。
- 一句话就是1. 模型和GPU内存没法一致,跑不了;2. I/O效率太低
本文的工作
- 设计重点:在单个商品GPU上设计高效的卸载策略来进行高通量的生成式推理。(目标变成了做offloading strategy)
- 实现方法:为了在GPU内存有限的情况下运行LLM,我们可以将其卸载到二级存储,并通过部分加载来执行部分计算。
- 依据原理:在一个典型的机器上,有3个层次的内存层次结构,就是GPU、CPU、Disk的结构。在面向吞吐量的场景中,我们可以通过使用大批量来牺牲延迟,并在一个大批量的输入中,在不同的内存层次结构之间摊销昂贵的I/O操作,与计算重叠。值得注意的是,在资源有限的情况下,延迟和吞吐量方面的性能明显劣于资源充足的情况。
- 遇到挑战:offloading+compression
- 卸载策略:在generative推理过程中有3种张量:weight,activation,key-value缓存。batch,token,layer之间的计算也构成复杂的计算图,现有的基于卸载的推理系统(2022年)继承了来自训练的策略,执行了过多的I/O,实现了远低于理论硬件限制的吞吐量。
- 压缩策略:prework已经证明了在压缩LLMs的权重和激活方面有很好的结果。然而,当结合压缩和卸载进行高通量推断时,权重和KV缓存的I / O成本和内存减少变得更为重要,这激发了替代的压缩方案。
- 总结一下:FlexGen,一个用于高通量LLM推理的卸载框架。FlexGen聚合来自GPU、CPU和磁盘的内存,高效地调度I/O操作,以及可能的压缩方法和分布式流水线并行。
- 问题变成设计offloading和compression策略,offloading需要考虑I/O,compression需要考虑权重、KV缓存的I/O cost和内存减少
用大的batch size将IO分摊到分级存储上,这操作和计算并行的。
本文贡献
- 本文贡献:searching spaces|compress by fine-grained groupwise quantization|demonstrate
searching spaces
- 定义可能的卸载策略的搜索空间,考虑计算调度、张量放置、计算委托(computation delegation)证明该搜索空间捕获了一个I / O复杂度在2 ×最优性以内的计算顺序。
- 然后,开发了一个基于线性规划的搜索算法来优化搜索空间内的吞吐量。该算法可以针对不同的硬件规格进行配置,并且可以很容易地扩展到包含延迟和吞吐量约束,从而帮助平滑地导航权衡空间(trade-off space)。
- 该算法可以针对不同的硬件规格进行配置,并且可以很容易地扩展到包含延迟和吞吐量约束,从而帮助平滑地导航权衡空间。
- 与现有的策略相比,我们的解决方案统一了权重、激活和KV缓存的放置,从而实现了更高的批大小上限,这是实现高吞吐量的关键。
compress by fine-grained groupwise quantization
- 证明对于OPT - 175B这样的LLMs,可以在几乎不损失精度的情况下,将权重和KV缓存压缩到4比特,而无需重新训练或校准。
- 这是通过细粒度的分组量化来实现的,适用于减少卸载时的I / O成本和内存使用。
demonstrate
- 我们通过在NVIDIA T4 ( 16GB ) GPU上运行OPT - 175B来展示FlexGen的效率。相比于深度零推理(DeepSpeed Zero-Inference)和Hugging Face Accelerate这两个最先进的基于卸载的推理系统,FlexGen往往允许更大数量级的批处理大小。因此,FlexGen可以获得更高的吞吐量。
- 在单个T4 GPU上,CPU DRAM为208GB,SSD为1.5 TB,输入序列长度为512,输出序列长度为32:
- 同样在5000秒的延迟下,FlexGen (有效批次大小为64 ,或者共2048个令牌)就可以实现比DeepSpeed Zero-Inference (批次大小为1 ,或者共32个令牌)高40倍以上的吞吐率,而Hugged Face Acceleration无法完成单个批次。
- 通过允许更高的延迟12000秒,FlexGen实现了比基线高69倍的最大吞吐量,因为它可以将有效批处理大小扩大到256个(总共生成了8192个令牌,256*32),而DeepSpeed Zero - Inference和Hugged Face Acceleration由于内存溢出问题无法使用大于2的批处理大小。
- 如果允许4位压缩,FlexGen可以通过保持CPU中的所有权重+摆脱磁盘卸载的方式达到100 ×高的最大吞吐量,有效批处理大小144 (共生成4608个令牌),延迟4000秒。
- 额外验证:我们还比较了基于FlexGen和Petals 两个代表性系统的卸载和分散集体推理。我们从分散式网络的时延和带宽以及输出序列长度等方面对两个系统进行了比较。结果表明,FlexGen在单GPU吞吐量方面优于分散的Petals集群,在某些情况下甚至可以实现更低的延迟。
额外问题:
- 这个搜索空间长什么样子?里面有什么?(应该是后面章节的内容)
- 一个批次有32个令牌?这个是哪里决定的,因为输出sequence length是32?我还是需要理解整个模型的运行过程和相关参数
- 怎么压缩到4bit的?
- fine-grained groupwise quantization细粒度的分组量化是什么?是另一篇论文(2020年的),针对基于注意力的模型提出组量化机制。将多头自注意力(MHSA)的密集矩阵中每个注意力头的矩阵 W 看作一个组https://cloud.tencent.com/developer/article/1583313,具体实现过程需要我了解吗?
related works
LLMs推理有两种方向:系统端和算法端。本文重点是系统端system side。
目前大部分推理系统专注于具有高端加速器的面向延迟的场景,所以作者要做在易于访问的硬件上部署以吞吐量为导向的推理。
为了要在商品级的硬件上实现llm推理,需要好的offloading,但是现在专注这个的只有DeepSpeed Zero-Inference 和 Hugging Face Accelerate这两种,它们的原理是继承训练系统的offloading技术,忽略了生成推理的特殊计算特性。他们没有利用面向吞吐量的LLM推理计算的结构,错失了I/O流高效调度的大好机会。(主流同行干了什么,缺点)
另一种在可访问硬件上实现LLM推理的尝试是Petals提出的协同计算。也有许多面向算法的工作,在LLM推断中放松某些方面的计算,以加速计算或减少内存占用,有稀疏化和量化两种方法。(同行,但是方向不一样)
在量化方面,先前的工作已经表明,在不压缩激活的情况下,可以将权重压缩到3比特,或者将权重和激活都压缩到8比特。(用的技术来源)
在FlexGen中,我们将权重和KV缓存都压缩到4位,并展示了如何将压缩和卸载结合起来做进一步的改进。(作者怎么搞的)
在更广泛的领域内,内存优化和卸载已经被研究用于训练和线性代数。
Background:LLM inference
LLM推理流程和内存占用情况
生成式推理
典型的LLM生成推理人物包含2种:1、预填充阶段,为LLM的每个transformer层按prompt顺序生成键-值缓存(KV cache);2、解码阶段利用并更新KV缓存来逐步生成令牌,其中当前令牌的生成依赖于先前生成的令牌。
其实就是编码+解码+时序
对一个特定的推理计算,定义
- batch size=b,
- 输入序列的长度=s,
- 输出序列的长度=n,
- transformer的隐藏尺寸=h1,
- 第二个MLP(多层感知机)的隐藏尺寸=h2,
- 总共transformer层数=l,
- 给定transformer层的权重矩阵wi K,wi Q,wi V,wi O∈R h1 × h1,w1∈R h1 × h2,w2∈Rh2 × h1。
内存分析
LLM推理的内存占用主要来自于模型权重和KV缓存。从OPT-175B的内存占用计算来看,资源充足的情况下,KV缓存成为大批量高通量推断的新瓶颈。
在FlexGen中,对于OPT-175B,我们将有效批处理大小放大到256,实现了0.69 token / s的吞吐率。
这一段的结果就是KV缓存是large-batch high-throughput inference的难点
吞吐量与延迟
延迟t定义为处理提示和生成所有令牌(总共b*n个,b=batch size,n=输出序列的长度)所花费的总秒数。
generation throughput=bn/t
Offloading Strategy
在本节中,我们不放松对LLM推理的任何计算,并说明如何在GPU、CPU和磁盘内存层次结构下形式化卸载过程。我们首先对问题进行建模,然后在FlexGen中构建可能的卸载策略的搜索空间。为了找到一个有效的策略,FlexGen建立了一个分析成本模型,并使用基于线性规划的优化器搜索配置。
问题公式化
一台机器上有3个设备:GPU、CPU和disk,构成三级存储层次结构,有速度+大小的内存区别(大家都懂),当一个LLM不能完全适应GPU内部时,我们需要将其卸载到二级存储中,并通过部分加载LLM来执行逐部分计算。
我们将带有卸载offloading的生成式推理建模为一个图遍历问题(graph traversal problem)。关注点是吞吐量throughput,所以假设一个给定的数据集有无穷多个需要处理的提示。
在图中,正方形表示一个layer上GPU batch的计算。具有相同颜色的正方形共享相同的层权重。我们定义一条有效路径为一条遍历所有正方形的路径,同时满足以下约束条件:
- 一个正方形能被计算:当且仅当跟它在同一行且在它左边的正方形都被计算过了
- 要在一个设备上计算一个正方形,它的所有输入(权重、激活、缓存)必须加载到同一个设备上。
- 一个正方形被计算后产生两个输出:激活和KV缓存。这些激活应该被存储,直到它的右同胞被计算出来。KV缓存应该存储,直到计算同一行上的最右。
- 在任何时候,存储在设备上的张量的总大小不能超过其内存容量。
目标是找到一条有效路径,最小化总执行时间,其中包括设备间移动张量时的计算开销和I/O开销。
搜索空间
根据以上公式,我们为FlexGen中可能的有效策略构建了一个搜索空间。
计算schedule
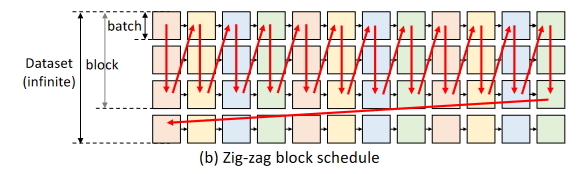
直观上进行遍历有两种顺序:逐行遍历和逐列遍历。所有现有系统都是逐行遍历的。因为它是最快的方式来完成一个批次的生成,并且KV缓存可以在连续一行之后立即释放。然而,由于每两个相邻的正方形不共享权重,该调度不得不重复加载权重,并产生巨大的I / O成本。
为了减少权值的I / O开销,我们可以逐列遍历图。列中的所有正方形共享权重,因此我们可以让权重停留在GPU上进行重用,并且只加载/卸载激活和KV缓存。但是由于激活和KV缓存仍然需要存储,所以我们不能一直遍历一个列到结束。因此,当它们填满CPU和磁盘内存时,我们不得不停止。
考虑到所有这些因素,我们收敛到一个锯齿形块时间表,如图所示。此外,我们还提出了另一种更高级的I / O最优调度,但由于最优调度的实际实现难度较大,我们只实现了更简单的块调度。然而,我们证明分块调度比附录A中的最优调度最多差2倍。
公式1
Z形块调度(zig-zag block schedule)的I / O复杂度在最优解的2 ×以内。
另一种典型的优化是重叠overlap。我们可以重叠下一层的权重负载,下一批次的缓存/激活负载,上一批次的缓存/激活存储,以及当前批次的计算。在块调度中添加重叠导致了算法1。
1 | Algorithm 1 Block Schedule with Overlapping |
最内层循环中的前六个函数可以看作是与六个逻辑线程并行启动的,因为它们之间没有依赖关系。最后一个函数对这6个逻辑线程进行同步。
我们依靠操作系统和CUDA驱动来解决底层硬件资源的调度问题。
作为结论,该算法在搜索空间中引入了两个参数:GPU的批大小GPU batch size和一个块中GPU的批数量the number of GPU batches in a block。GPU批次大小与GPU批次数量的乘积称为分块大小(或有效批量)block size (or effective batch size)。
张量放置
除了计算调度之外,一个策略应该指定如何在内存层次结构中存储这些张量。
我们使用三个变量wg、wc和wd分别定义存储在GPU、CPU和磁盘上的权重百分比。类似地,我们使用三个变量hg,hc,hd来定义激活的百分比,并使用cg,cc,cd来定义KV缓存。
给定百分比,张量的划分仍然有多种方法。以权重张量为例,从粗粒度到细粒度,可以在模型粒度(例如,将模型中50 %的层分配给GPU)、层粒度(例如,将一个图层中50 %的张量分配给GPU)或张量粒度(例如,将张量中50 %的元素分配给GPU)上进行权重划分。
较粗的粒度会导致较低的运行时开销,但其灵活性较差且成本难以分析。考虑到运行时开销和所需的灵活性,我们使用层粒度layer granularity作为权重,使用张量粒度作为激活和KV缓存。
计算委托
虽然CPU比GPU慢得多,但我们发现在某些情况下使用CPU计算仍然是有益的。这是因为解码过程中注意力分数的计算是I / O有界的。
考虑KV缓存存储在CPU上的情况。在GPU上计算注意力分数需要将整个KV缓存移动到GPU上,由于KV缓存巨大,因此会产生大量的I/O开销。相比之下,在CPU上计算注意力分数不需要移动KV缓存。它只需要将激活从GPU移动到CPU。
定量地,令b为GPU批处理尺寸,s为序列长度,h1为隐藏尺寸。移动的KV缓存大小为b × s × h1 × 4字节,移动的激活大小为b × h1 × 4字节,因此在CPU上计算注意力分数可以减少s ×的I / O。对于长序列(例如, s≥512 ),如果不在GPU上存储相关的KV缓存,最好在CPU上计算注意力分数。
成本模型与策略搜索
4.2节中的调度和放置构造了一个具有多个参数的搜索空间。现在我们开发了一个分析成本模型来估计给定这些算法参数和硬件规格的执行时间。
成本模型
成本cost模型预测一层预prefill过程中的延迟,记为Tpre;预测一层解码过程中单GPU块的平均延迟,记为Tgen。计算一个块的总延迟可以估计为 \(T = T_{pre} \cdot l + T_{gen} \cdot ( n-1 ) \cdot l\), 其中l为层数,n为生成的令牌数。
假设完全重叠perfect overlap,Tpre可以估计为\(T_{pre} = max( ctog^p、gtoc^p、dtoc^p、ctod^p、comp^p)\),其中ctogp,gtocp,dtocp,ctodp,compp分别表示预填充一层时CPU到GPU的读、GPU到CPU的写、磁盘到CPU的读、CPU到磁盘的写、计算的延迟。
类似地,Tgen可以估计为\(T_{gen} = max( ctog^g , gtoc^g , dtoc^g , ctod^g , comp^g)\),其中ctogg、gtocg、dtocg、ctodg、compg分别表示从CPU到GPU的读取、从GPU到CPU的写入、从磁盘到CPU的读取、从CPU到磁盘的写入、计算的延迟。
对于dtocg等I / O项,通过对I / O事件进行求和来估计,I / O事件包括权重、激活和缓存读取。
一个Transformer层的FP16权重大小为\(8h^2_1 + 4h_1 \cdot h_2\)字节,其中h1表示隐藏大小,h2表示第二个MLP层的隐藏大小。
令bls为块大小,s为提示长度;则一层的激活大小为2 · bls · h1。平均一层的KV缓存大小为4 · bls · ( s + n/2) · h1。
分别从磁盘加载wd、hd、cd百分比的权重、激活和KV缓存,使磁盘读取总延迟\(dtoc^g=\frac{1}{disk to cpu bandwidth} ( ( 8h^2_1 + 4h_1 \cdot h_2) \cdot wd + 4 \cdot bls \cdot ( s + \frac{n}{2}) \cdot h_1 \cdot cd + 2 \cdot bls \cdot h_1 \cdot hd )\)。
同样对于计算项,我们总结了所有的计算事件,包括CPU和GPU上的矩阵乘法和批处理矩阵乘法。除了延迟估计,我们还估计了GPU、CPU和磁盘的内存使用峰值,然后我们添加了内存约束。全成本模型见附录A.3。
策略搜索
一个策略包括11个变量:块大小bls,GPU批处理大小gbs,权重放置wg,wc,wd,激活放置hg,hc,hd,KV缓存放置cg,cc,cd。在实际中,百分比不能是介于0和1之间的任意实数,因为张量不能任意分裂。
然而,我们将成本模型中的百分比变量放宽为0到1之间的任何实数,因为它是逐渐变化的。我们将该问题作为一个双层优化问题进行求解。我们首先列举了( bls , gbs)元组的几种选择。
通常情况下,gbs是4的倍数,bls小于20,因此没有太多的选择。那么在固定bls,gbs的情况下,求最优布局p = ( wg , wc , wd , cg , cc , cd , hg , hc , hd)就变成了一个线性规划问题,如上式所示。( 1 ) .由于该线性规划问题只有9个变量,可以非常快速地求解。该公式还可以灵活地扩展到包括延迟约束和压缩等模型近似方法。

为了使用成本模型,我们在硬件上运行仿形来采样一些数据点,并拟合硬件参数。然后我们调用优化器得到卸载策略。由于我们的松弛和准确建模峰值内存使用量(例如,碎片化)的困难,有时来自策略搜索的策略可能耗尽内存。在这种情况下,我们对政策进行了手工微调。成本模型通常可以返回一个好的策略,但通常可以通过手动调优来获得更好的策略。
拓展到多个GPU上
我又忘了这几个参数是表示什么的了: - n:输出序列的长度 - l:transformer层的总数 - m:在这一节提出来的,在m个GPU上等分l层LLM来使用流水线并行
- 问题:当FlexGen中存在多个GPU时,如何对卸载策略进行扩展
- 为什么要考虑这个问题:虽然可以为一个GPU找到一个接近最优的策略,但该策略仍然严重受限于I / O,并且GPU利用率较低。
- 一种思路:可以利用模型并行来减少每个GPU的内存压力,这可能会导致解码中的超线性缩放super-linear scaling in decoding。
- 问题来到模型并行了:两种并行:张量并行和流水线(pipeline)并行
- 张量并行可以降低单次查询延迟,而流水线并行由于其较低的通信成本可以实现吞吐量的良好扩展。
- 由于以吞吐量为目标,FlexGen实现了流水线并行。
- 问题来到流水线并行:
- 实现:我们通过在m个GPU上等分l层LLM来使用流水线并行,然后所有GPU的执行遵循相同的模式。
- 具体:问题归结为在一个GPU上运行一个n / m层的transformer。可以直接重用(为一个GPU开发的)策略搜索policy search。
- 为了实现微批流水线,在算法1中增加了一个新的for - loop,将迭代级流水线并行执行调度与我们的单设备卸载运行时间相结合。
Approximate Methods
上一节的重点是精确计算。然而,通过允许一些近似,推理吞吐量可以大大提高,而精度损失可以忽略不计,因为LLMs通常对仔细的近似(?careful approximations)具有鲁棒性。这一部分介绍了两种这样的近似:分组量化和稀疏注意力。
分组量化 Group-wise Quantization
- b:batch size
我们证明了在OPT - 175B上,权重和KV cache都可以直接量化为4比特整数,而无需任何重新训练或校准,同时保持相似的精度( 6.2节)。与一些试图使用整数矩阵乘法来加速计算的相关工作相比,在我们的情况下,量化的目标主要是为了压缩和减少I / O成本。因此,我们可以选择有利于高压缩比的细粒度量化格式,并在计算前将张量解量化回FP16。我们使用了一种细粒度的分组非对称量化方法(fine-grained group-wise asymmetric quantization method)。
给定一个张量,我们沿某一维度选择g个连续的元素作为一个组group,对于每个group,我们计算该组元素的最小值和最大值,并将每个元素x量化为b比特整数\(x_{quant} = round (\frac{x-min}\times( 2b-1 ) )\).
张量以量化格式存储,并在计算前转换回FP16。由于权重和KV缓存都消耗了大量的内存,我们将两者压缩到4位,组大小为64。有多种方法可以选择哪个维度进行分组。我们发现,将权重沿输出通道维度分组,KV缓存沿隐藏维度分组,在保持精度的同时,在实际中具有运行效率。
值得一提的是,FlexGen中这种细粒度的分组量化在压缩和解压方面造成了一定的开销。如果运行在CPU上使得CPU委托无用,这样的开销可能是非常重要的,因此我们在启用量化时关闭CPU委托。同时,( 2022年德特默斯&泽特尔莫耶)的工作还发现,在OPT模型上,4比特精度对于总模型比特和零样本精度几乎是最优的。与之前的工作相比,我们首先提出压缩KV缓存,并在OPT - 175B上展示结果。
稀疏注意力 Sparse Attention
我们证明了只需在OPT - 175B上加载前10 %的注意力值缓存,就可以利用自注意力的稀疏性,同时保持模型质量。我们给出一个简单的Top - K稀疏近似。在计算注意力矩阵之后,对于每个查询,我们从K个缓存中计算其Top - K令牌的索引。然后,我们简单地丢弃其他令牌,并根据索引只加载V缓存的一个子集。
这些近似的应用是直截了当的。我们展示了这些初步但有趣的结果,并打算强调FlexGen是一个通用框架,可以无缝地插入许多近似方法。
Evaluation
- hardware
- Google Cloud的NVIDIA T4 GPU实例上运实验。
- 硬件指标:
- GPU:NVIDIA T4 16 GB
- CPU:Intel Xeon @ 2.00GHz 208 GB
- Disk:Cloud default SSD (NVMe) 1.5 TB
- SSD的读取带宽约为2GB / s,写入带宽约为1GB / s。
- 我们的方法和实现不依赖于特定的硬件架构。有些架构(例如,统一存储)可能对我们的方法更友好。关于不同硬件设置的讨论和实验见附录A.4。
- model
- OPT模型( Zhang et al , 2022)的6.7 B到175B参数被用于评估。
- 虽然我们没有对其他模型进行评估,但是FlexGen中的卸载可以应用于其他变压器LLM,例如GPT - 3 (布朗等, 2020)、PaLM ( Chowdhery et al , 2022)和BLOOM ( Scao et al , 2022),因为它们具有相似的结构。
- workload
- 我们的关注点是在给定的数据集上进行高通量生成。我们使用了合成数据集,其中所有的提示都填充到相同的长度。系统需要为每个提示信息生成32个令牌。
- 我们测试了两种提示长度:512和1024 (对于更多设置下的实验,见附录A.4)。评价指标为生成吞吐量,定义为生成令牌数/ (预填充时间+解码时间)。有时候,对于某些系统来说,运行一个完整的批需要花费太长的时间- -在这种情况下,我们生成的令牌更少,并预测最终的吞吐量。
- 我们在所有系统的吞吐量基准中使用虚拟模型权重,在准确性评估中使用真实权重。
- baseline
- 我们使用Deep Speed ZeRO - Inference (阿米那巴迪等, 2022)和Huging Face Speed (拥抱面孔, 2022)作为基线。它们是唯一可以在没有足够GPU内存的情况下通过卸载来运行LLM的系统。DeepSpeed支持将整个权重卸载到CPU或磁盘上。如果有多个GPU,则使用ZeRO数据并行。加速支持卸载重量的一部分。它不支持不同机器上的分布式GPU。两者都采用逐行调度,只能在GPU上进行缓存/激活。这些系统支持不同的量化方法。
- 然而,加速中的量化与卸载不兼容,深速中的量化不能保持精度达到175B,因此我们不在这些系统上启用量化。除了卸载,去中心化协同推理是降低LLM推理资源需求的另一种选择。因此,我们也将Petals (博尔祖诺夫et al , 2022 ;里亚比宁et al , 2023)作为额外的基线。
- implementation
- FlexGen是在PyTorch ( Paszke等, 2019)的基础上实现的。
- FlexGen通过计算将多个CUDA流和CPU线程管理到重叠I/O。
- FlexGen为存储在磁盘上的张量创建文件,并将其映射为虚拟内存以访问它们。
offloading
最大吞吐量基准
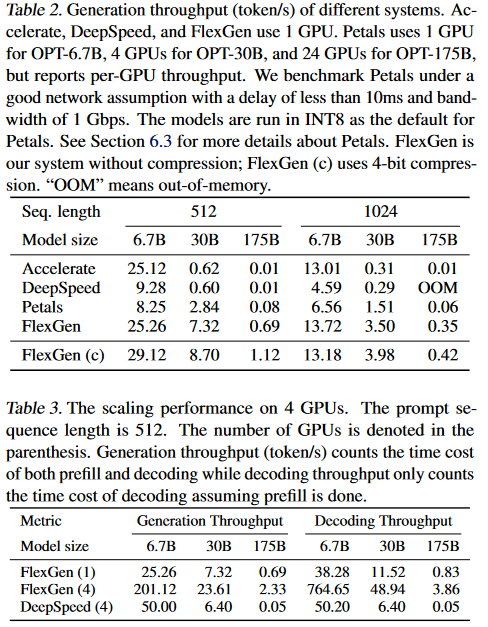
首先评估一个GPU在两个提示长度(Seq. length)下系统所能达到的最大生成吞吐量,如表2所示,FlexGen在所有情况下都优于所有的基线。
在不同model size下3种算法
- 在OPT6.7B上
- Accelerate和FlexGen可以成功地将整个模型拟合到单个GPU中,因此选择只使用GPU。
- DeepSpeed有较高的内存开销,无法将OPT - 6.7 B适配到GPU中,因此使用较慢的CPU卸载。
- 在OPT - 30B上,所有系统均切换为CPU卸载。
- Deep Speed和Acceleration将KV缓存存储在GPU上,因此无法使用非常大的批处理大小,
- 而FlexGen将大部分权重和所有KV缓存卸载到CPU上,实现了更大的GPU批处理大小。
- 此外,FlexGen通过块调度实现了权重的重用。
- 在OPT - 175B上,所有系统都开始将权重卸载到磁盘上。
- 基线系统只能使用2的最大批处理大小,而FlexGen可以使用32的GPU批处理大小和32 × 8的块大小,实现了69 ×高的吞吐量。
- 在启用压缩的情况下,FlexGen在单GPU上实现了112 ×更高的生成吞吐率,提示序列长度为512。
- 这一巨大的改进是由于FlexGen使用了144的有效批处理大小,并将权重和KV缓存压缩到CPU内存中,以避免磁盘交换缓慢。
- 关于策略设置和有效批次大小的更多细节可参见附录A.4。关于磁盘规格如何影响吞吐量的更多实验见附录A。4 .
表3给出了4台机器上的结果,每台机器上有1个GPU。OPT - 30B或OPT - 175B仍然无法适应4个GPU。自然地,我们可以以数据并行的方式运行4个独立的FlexGen,以获得吞吐量的线性缩放。但这里我们表明,流水线并行可以实现译码吞吐率的超线性缩放。
通过流水线并行,每台机器的内存压力被降低,因此我们可以从小批量切换到大批量,或者从磁盘卸载切换到CPU卸载。在表3中,FlexGen没有实现对生成吞吐量(其中同时考虑了预填充和解码的时间开销)的线性扩展。这是因为在预填充阶段存在管道气泡,而我们的工作负载设置仅产生32个令牌。然而,FlexGen在解码吞吐率(在假定预填充已经完成的情况下,只计算解码时间开销)上实现了超线性扩展。这意味着如果我们生成更多的令牌,流水线并行将显示出它的好处,因为解码时间将占主导地位。
感觉这里把表格画成折线图会更加直观点 为什么要设置2个提示长度呢? 看不懂,acceleratepetals和flexgen都是算法?还是模型
延迟-通量权衡
我们在图1中配置了这些系统,以在各种延迟限制下实现最大吞吐量,并绘制了它们的延迟-吞吐量权衡曲线。FlexGen设置了一个新的Pareto最优前沿,显著优于基线。在低延迟方面,FlexGen支持部分卸载,并使用了更多的权重空间。
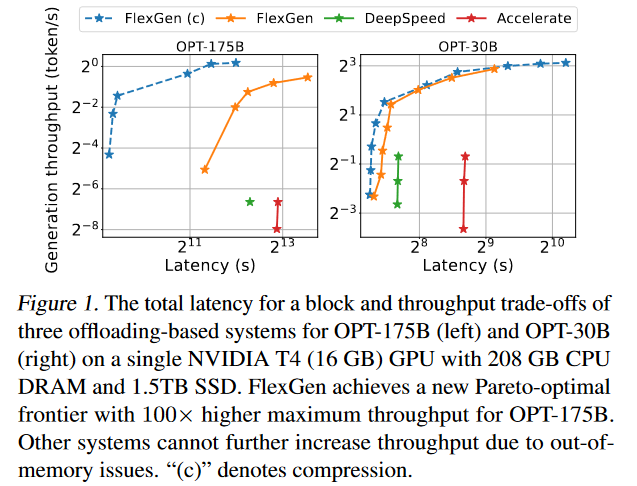
在高通量那一侧,FlexGen积极地将所有的东西卸载到GPU之外,以实现大的GPU批量大小和块大小。在相同的5000秒延迟要求下,无压缩的FlexGen可以实现比DeepSpeed和Acceleration高40倍的吞吐量。如果允许更高的延迟和压缩,FlexGen可以进一步提升吞吐量,并使用144的有效批处理大小达到100倍的提升。在这种情况下,压缩可以使FlexGen适应CPU内存中的所有东西,并避免磁盘I/O,详细的延迟、吞吐量和策略设置可以在附录A中找到。
运行时故障
我们在附录A的表8中展示了OPT - 175B在FlexGen上的运行时故障。4 .我们禁用了重叠,并对主要组件使用的时间进行了描述。预填充和解码的GPU计算利用率分别为82 %和13 %。
消融学习
然后,我们将每个单独的技术所带来的改进隔离开来。表4列出了如果一次性禁用一种技术,FlexGen可以达到的吞吐量。在OPT - 30B上,在启用所有优化的情况下,将20 %的权重放在GPU上,80 %的权重放在CPU上,所有的激活和KV缓存都放在CPU上。同样选择GPU批处理大小为48,分块大小为48 × 3′。没有策略搜索"说明了较差策略的表现,表明了一个好的策略的重要性。在这两个模型上,使用CPU计算和重叠带来了非平凡的改进。我们还将DeepSpeed / Acceleration中使用的策略移植到FlexGen运行时中,显示其策略的次优性。更详细的消融研究见附录A。4。
HELM和数据争议
我们通过评估一个尚未纳入HELM官方发布的新模型OPT - IML - 30B ( Iyer et al , 2022)来测试FlexGen与HELM ( Liang et al , 2022)的交互。FlexGen在表1所述的硬件设置下,在21小时内完成了7个代表性子场景的基准测试,包含了所有的系统开销。附录A.4中的表9显示了任务的详细信息和相应的运行时间。我们还使用FlexGen来运行带有OPT模型的数据争用任务(纳拉扬et al , 2022)。详细的任务配置和运行时间见附录A。4。
Approximations
我们使用两个任务来表明我们的近似方法表现出可忽略的精度损失:Lambada (帕佩尔诺等, 2016)上的下一词预测和WikiText ( Merity et al , 2016)上的语言建模。如表5所示,' 4bit '是指使用分组量化将权重和KV缓存压缩为4比特整数。' 4-bit-S '是将量化和稀疏注意力相结合,在值缓存上采用10 %的稀疏度。与FP16相比,这两种方法的精度损失可以忽略不计。结果揭示了LLMs对这些近似的稳健性。我们也尝试了3位压缩,但不能保持精度。
Offloading vs. Collaborative Inference
我们通过在GCP上设置一个私有的Petals集群,每个节点有一个T4 GPU,在不同的网络条件下对FlexGen和Petals进行了比较。我们使用Linux流量控制来限制实例之间的连接,以模拟一个真实的去中心化网络,并对OPT - 30B模型(输入序列长度: 512 ,输出序列长度: 32)的性能进行了测试。我们将每个请求的批处理大小调整为2,并通过6个并行的客户机进程发出请求,以达到最大吞吐量2。
此外,我们将Petals的吞吐量通过使用的GPU数量进行归一化处理。如图4所示,我们发现在所有测试的网络条件下,使用单个T4的FlexGen的吞吐量都优于Petals集群的每GPU吞吐量。花瓣不使用卸载,因此它不能使用非常大的批大小,这限制了它在吞吐量上的扩展。因此,我们认为卸载可能是一种比在分散的长管道中通信大量激活更有效的吞吐量解决方案;另一方面,在对延迟更敏感的场景中,协同推理可能是更可行的选择。
有趣的是,我们发现FlexGen在生成时间较短的慢速网络中可以获得比Petals更低的延迟。我们推测这是由于网络带宽成为激活传输的瓶颈,较大的延迟会对管道中的每个通信步骤造成显著的开销。对于100ms延迟网络的曲线,我们可以观察到FlexGen和Petals之间的一个交叉点。这是因为预填充时的激活比解码时的激活要大一个输入序列长度的因子。因此,通信开销成比例地变大,这显著地减缓了预填充过程中的Petals。
Conclusion
我们介绍了一个用于LLM推理的高通量生成引擎FlexGen,它专注于资源受限场景下对延迟不敏感的批处理任务。
个人总结
abstract
高吞吐量(high throughput)LLM、灵活配置flexble在不同的硬件、解决线性规划问题来访存tensor、在不损失精度的前提下将权重和注意缓存压缩到4bit
introduction
面向吞吐量的生成式推理、用大的batch size将IO分摊到分级存储上、设计offloading和compression策略,offloading需要考虑I/O,compression需要考虑权重、KV缓存的I/O cost和内存减少。
这一章里面还有个本文贡献,后面的章节会总结到,不写了。
related work
问题
- abstract遗留:flexgen的特点:通过聚合来自GPU、CPU和磁盘的内存和计算,FlexGen可以在各种硬件资源约束下灵活配置。灵活配置怎么配置的
- 先进的offloading system有哪些?(就是同行,我也没找到,过会儿去实验那一章找找),flexgen和别的offloading system对比
- introduction遗留:搜索空间是什么
- fine-grained groupwise quantization细粒度的分组量化是什么?是另一篇论文(2020年的),针对基于注意力的模型提出组量化机制。将多头自注意力(MHSA)的密集矩阵中每个注意力头的矩阵 W 看作一个组https://cloud.tencent.com/developer/article/1583313,具体实现过程需要我了解吗?
- 怎么压缩到4bit的?compress策略的问题
待解决的问题
- flexgen是什么,算法?
- introduction里面说的:本文介绍了FlexGen,这是一个用于在GPU内存有限的情况下运行LLM的高通量生成引擎。 engine,加速引擎?
- 怎么想到要做这个的?
- 做推理的llm有哪些?(论文2. related work上看的)
- FasterTransformer (NVIDIA, 2022),
- Orca (Yu et al., 2022),
- LightSeq (Wang et al., 2021),
- PaLM inference (Pope et al., 2022),
- TurboTransformers (Fang et al., 2021),
- DeepSpeed Inference (Aminabadi et al., 2022),
- Hugging Face Accelerate (HuggingFace, 2022)
- 这些做推理的LLM有什么不足?
- 做推理的llm有哪些?(论文2. related work上看的)
- high-throughput对LLM的影响是什么?
真心看不懂;-;等看完下一篇再回过头来看这个吧,泪目。