LISA: Layerwise Importance Sampling for Memory-Efficient Large Language Model Fine-Tuning
百篇paper计划(6/100),好像是LoRA的改进,随便找的,而且这篇还没投会议呢。
这一篇也是微调,改lora
我以前看论文居然这么龟毛orz我的百篇paper计划创业未半而中道崩殂啊
- 论文标题:LISA: Layerwise Importance Sampling for Memory-Efficient Large Language Model Fine-Tuning
- code:github
- 打标签:微调
- 时间:2024年5月28日
因为重点是论文的idea和实现过程,实验结果不包括分析的话就删节掉了。
abstract
- 同行:低秩自适应( Low-Rank Adapting,LoRA ),不够完全参数训练,因为lora将参数搜索限制在低秩子空间中。
- 理论研究
- LoRA在微调任务上的逐层性质(layerwise properties)
- 观察到不同层之间权重范数的意外但一致的偏度unexpected but consistent skewness of weight norms across different layers
- 成果
- Layerwise Importance Sampled AdamW ( LISA ),lora的替代方案
- 在广泛设置中优于LoRA和全参数训练,并且内存成本与LoRA一样低。
- 将重要性采样(importance sampling)的思想应用于LLMs中的不同层,并在优化过程中随机冻结(freeze)大多数中间层。
Introduction
- 研究方向:对LLM微调
- 同行:高效参数微调PEFT
- adapter weights
- prompt weights
- LoRA(因其独特的将适配器合并回基模型参数的能力而脱颖而出)
- LoRA的问题:
- 没法在所有设置中超越全参
- 大规模数据集上表现不行
- 我们将这归因于LoRA的可训练参数比基模型少得多,这限制了LoRA训练的表示能力。
- 研究LoRA
- 研究了LoRA在每一层的训练统计量
- 发现LoRA的逐层权重规范(layerwise weight norms)具有不寻常的偏态分布(skewed distribution),其中底层和/或顶层在更新期间占据了大部分权重。
- 相比之下,其他的自注意力层只占少量,这意味着不同的层在更新时具有不同的重要性。
- 根据不同层的重要性来"采样",重要性采样的思想
- 成果
- 逐层法Importance Sampled Adam ( LISA )算法
- 通过选择性地更新仅重要的LLM层而不接触其他层,LISA能够以较少或类似于LoRA的内存消耗来训练大规模语言模型(≥65B参数)。
- 在下游任务上进行微调后,LISA的性能优于LoRA和传统的全参数微调方法
- 贡献
- 在LoRA中发现了跨层的权重范数分布倾斜的现象,这意味着不同层在大规模LLM训练中的重要性不同
- 提出了逐层法Importance Sampled Adam W ( LISA ),这是一种简单的优化方法,能够以更少或类似于LoRA的内存成本扩展多达70B个LLM
- 展示了LISA在现代LLM微调任务中的有效性,LISA表现出比LoRA更好的收敛行为。
Related Work
这一章的内容不是很重点,就是相关技术和目前进展而已,主要设计lora+冻结。
LLM
低资源场景下对大规模模型(≥65B )进行微调变得不可行。
PEFT
参数有效微调( PEFT )方法通过仅对参数子集进行微调来适应预训练模型。可以分为3类:
- Prompt Learning methods 强调用冻结的模型参数优化输入令牌或输入嵌入,通常在所有三种类型中具有最小的训练成本。
- Adapter methods 会引入比原始模型参数少得多的辅助模块,在训练时只对适配器模块进行更新。
- Selective methods 与它们相比,选择性方法与LISA的关系更为密切,LISA侧重于在不增加额外模块的情况下优化模型参数的一部分。
通过冻结layer引入了几个技术:
- AutoFreeze 提供了一种自适应机制来自动识别冻结层,并加速训练过程
- FreezeOut逐步冻结中间层,在不显著影响准确率的情况下显著减少训练时间
- SmartFRZ框架使用基于注意力的预测器进行层选择,在保持精度的同时大幅减少计算和训练时间
- 然而,这些层冻结策略由于其固有的复杂性或与现代记忆还原技术的不兼容性,都没有在大语言模型的背景下被广泛采用
LoRA
- 低秩自适应( Low-Rank Adaptation,LoRA )技术在普通的LLM训练中更为普遍。
- 技术原理:LoRA通过使用低秩矩阵来减少可训练参数的数量,从而减少计算负担和内存成本。
- 优点
- 一个关键优势是它与具有线性层的模型的兼容性,其中分解后的低秩矩阵可以合并回原始模型。这样可以在不改变模型架构的情况下进行高效的部署。
- LoRA可以与其他技术无缝结合,如量化quantization或混合专家(MoE)。
- 缺点
- LoRA的性能与全参数微调并不具有普遍可比性。已有任务LoRA的表现比全参数训练差很多。
- 这种现象在大规模的预训练环境中尤为明显,据我们所知,成功的开源LLMs只采用了全参数训练。
Large-scale Optimization Algorithms
- 除了改变模型结构的方法外,也有提高LLMs优化算法效率的努力。
- 其中一种方法是逐层优化 layerwise optimization
- 之前的逐层优化
- 深度信念网络( Deep Belief Networks,DBN )引入了一种有效的逐层预训练方法,证明了顺序层优化的好处。
- 这一想法被扩展后,他们说明了一种贪婪的、无监督的方法来预训练每一层深度网络的优势。
- 之前的逐层优化
- 在大批量训练的背景下
- 开发了LARS和LAMB(这两个都是优化算法),以提高泛化能力并减轻与大批量训练相关的性能下降。
- 尽管有这些创新,Adam 和Adam W 仍然是大多数LLM设置中使用的主要优化方法。
其他降低LLMs训练成本的尝试:
- 零阶优化MeZO,在训练过程中带来了显著的内存节省。然而,它在多个基准测试中也引起了相当大的性能下降,特别是在复杂的微调场景中。
- 在加速方面,Sophia将裁剪后的二阶信息融入到优化中,在LLM训练上获得了非平凡的加速比。显著的缺点是其Hessian估计的内在复杂性和在大尺寸模型(例如,≥65B)中未被验证的经验性能。
- 与我们的工作平行,提出了GaLore,一种存储高效训练策略,通过将梯度投影到低秩紧凑空间来降低内存开销。
- 然而,在微调设置中的性能仍然没有超过全参数训练。综上所述,LoRA-variant methods和Adam W仍然是大尺度LLM微调的主导范式,其性能仍需进一步改进。
Method
Motivation
- 为了了解LoRA如何仅用几个参数实现有效的训练,对多个模型进行了实证研究,特别是不同层之间的权重规范weight norms across various layers。
- 数据集:Alpaca - GPT4数据集上微调
- 在训练过程中,记录了更新后每一步t的每一层l的平均权重范数,即: \[\mathbf{w}^{(\ell)}\triangleq\text{mean-weight-norm}(\ell)=\frac1T\sum_{t=1}^T\|\theta_t^{(\ell)}\|_2 \] 其中l是层数,t是step步数,theta是模型更新后的权重,norm就是取模
- 实验结果
- x轴代表层id,从嵌入权重(embedding weights)到最后一层,y轴量化权重范数。
- 在LoRA中,嵌入层(embedding layer)或语言模型头层(head layer)表现出明显大于中介层(intermediary layers)的权重规范(weight norm),通常为数百倍。然而,这种现象在全参数训练设置下并不显著。
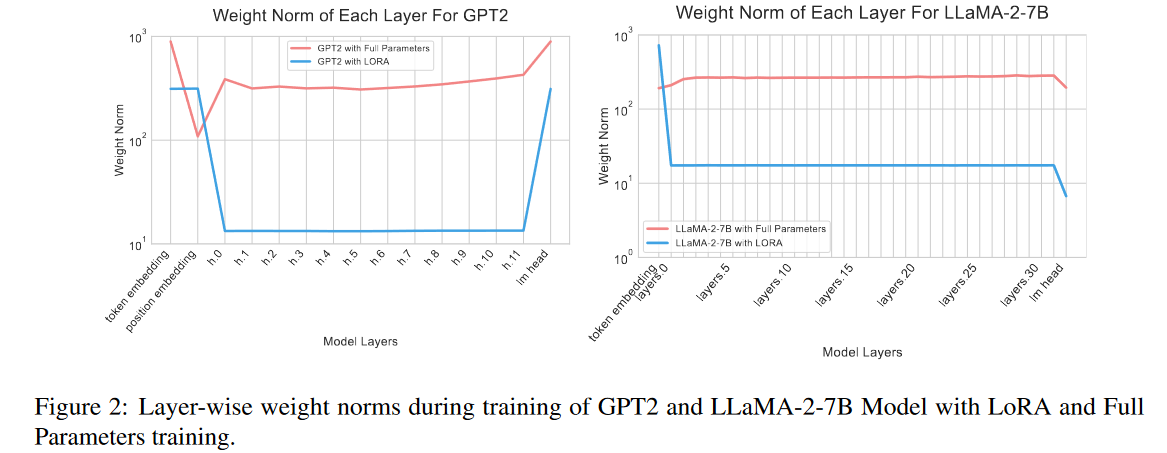
- 图的x轴从左到右依次是embedding权重(token embedding和position embedding),然后是神经网络的若干层,最右边是LM的head
- 在GPT2上面就2个都高,在LLaMA--2-7B上面只有嵌入层高
- 认知
- LoRA和全参数训练的更新侧重点存在显著差异,这可归因于两者学习到的知识不同。
- 例如,在嵌入层中,具有相似意义的标记,即同义词,可以被投影到相同的嵌入空间中,并转换为相似的嵌入。LoRA可以捕获语言中的这种相似性,并在低维空间中对其进行"分组",从而使语言意义的频繁特征能够被及时识别和优化。代价是LoRA受限于其内在低秩空间的表征能力有限
- 尽管对这一观察结果有各种不同的解释,但有一个事实仍然是明确的:LoRA对分层重要性的评价不同于全参数调整。
Layerwise Importance Sampled AdamW (LISA)
- 希望通过采样不同的层进行冻结freeze来模拟LoRA的更新模式。这样,我们可以避免LoRA固有的低秩表示能力有限的缺陷,并模拟其快速学习过程。
- 直观来说,在层之间给定相同的全局学习率(global learning rates across layers),LoRA中权重范数(weight norm)较小的层也应具有较小的采样概率以在全参数设置中解冻,从而使跨迭代的期望学习率保持一致。
- 这就是重要性采样(importance sampling)的思想,不是在全参数设置中应用逐层不同的学习率{ ηt }来模拟LoRA的更新{ \(\tilde{\eta}_t\) },而是应用采样,然后得到相同的期望参数更新
- \[\eta_t^{(\ell)}=\tilde{\eta}_t^{(\ell)}\cdot\frac{\tilde{\mathbf{w}}^{(\ell)}}{\mathbf{w}^{(\ell)}}\quad\Rightarrow\quad\eta_t^{(\ell)}=\eta^{(\ell)},p^{(\ell)}=\frac{\tilde{\mathbf{w}}^{(\ell)}}{\mathbf{w}^{(\ell)}}\]
- 这就产生了我们的分层重要性采样AdamW方法,如算法1所示。
- 在实际应用中,由于LoRA中除底层和顶层外的所有层都具有较小的权重范数,我们在实际中采用\(\{ p_\ell\} ^{N_L} _{\ell = 1} = \{ 1.0,\gamma / NL,\gamma / NL,..,\gamma / N_L,1.0 \}\),其中\(\gamma\)控制优化过程中期望的解冻层数。
- 直观上,\(\gamma\)作为一个补偿因子来弥合LoRA和全参数调优之间的差异,让LISA模拟与LoRA类似的逐层更新模式。
- 为了进一步控制实际设置中的内存消耗,我们每次随机采样\(\gamma\)层,以在训练期间提高未冻结层最大数量的上限。
\[\begin{aligned}& \textbf{Algorithm 1 Layerwise Importance Sampling AdamW (LISA)}\\&\overline{ \textbf{Requitre: } \text{number of layers }N_L,\text{number of iterations }T,\text{sampling period }K,\text{number of sampled layers }\gamma,\text{initial earning rate }\eta_0}\\ &1:\mathrm{~for~}i\leftarrow0\mathrm{~to~}T/K-1\mathrm{~do}\\ &2:\quad\text{Freeze all layers except the embedding and language modeling head layer}\\ &3:\quad\text{Randomly sample }\gamma\text{ intermediate layers to unfreeze}\\ &4:\quad\text{Run AdamW for }K\text{ iterations with }\{\eta_t\}_{t=ik}^{ik+k-1}\\ &5:\textbf{end for}\end{aligned}\]
- 算法解读(论文中的伪代码写得不太好,我试试看看源代码)
- T/K-1次迭代:T/K=总共进行的sample次数,step1的for循环就搞(sample次数)次
Experimental Results
Memory Efficiency
我们进行了峰值GPU内存实验(peak GPU memory experiments),以展示LISA的内存效率,并展示其与LoRA相当或更低的内存成本。
实验设置
- 从Alpaca数据集中随机采样prompts,并将最大输出令牌长度限制为1024。
- 我们关注两个关键的超参数:LoRA的秩rank和LISA的激活层数。
- 对于其他超参数,从120M到70B参数的5个LLMs始终使用1的小批量大小
- 故意排除其他节省GPU内存的技术,如梯度检查点radient checkpointing、卸载offloading和闪存注意力flash attention。
- 所有的内存效率实验都是在内存为80G的4 × NVIDIA Ampere Architecture GPU上进行的。
结果
- table 1
- 图表上的表示
- E 表示嵌入层,
- H表示语言建模头层,
- 2L 表示另外两个中间层。
- 结果
- LISA配置,特别是当嵌入层( E )和两个附加层( E + H + 2L )同时增强时,与LoRA方法相比,在微调LLaMA - 2 - 70B模型时显示出相当大的GPU内存占用减少。具体来说,LISA E + H + 2L配置显示峰值GPU内存从LoRA Rank 128配置所需的79G减少到75G。
- 这种效率增益并不是一个孤立的事件;在不同的模型结构中观察到了系统性的内存使用减少,这表明LISA的激活层方法本质上具有更高的内存效率。
- 图表上的表示
- figure 3
- 结果
- 值得注意的是,LISA中的内存减少使得LLaMA - 2 - 7B可以在单个RTX4090 ( 24GB ) GPU上进行训练
- 特别地,由于LISA没有引入适配器带来的额外参数,因此它比LoRA需要更少的激活内存消耗。
- LISA的激活记忆甚至略低于全参数训练,因为带有deepspeed的pytorch 允许在反向传播之前删除冗余激活。
- 结果
- figure 4
- 结果
- LISA内存占用的减少也会导致速度的加快。
- 与全参数训练相比,LISA提供了近2.9倍的加速比,与LoRA相比,LISA提供了近1.5倍的加速比。部分归因于adapters结构的去除。
- LoRA和LISA中memory足迹的减少都导致了前向传播的显著加速,强调了存储高效训练的重要性。
- 结果
Q:
- batch size设置成1感觉好奇怪啊
- 为什么LoRA的activation memory比baseline多一点
- 为什么lisa的gradient memory和optimizer memory比lora多一点
- weight|activation|gradient|optimizer memory都是什么
- adapters结构会拖慢训练速度?
Moderate Scale Fine-Tuning
LISA可以实现这种显著的内存节省,同时在微调设置下仍然获得有竞争力的性能。
实验设置
- 为了证明LISA比LoRA的优越性
- 在Alpaca GPT - 4数据集 (由GPT-4生成的52k个会话对组成)的指令跟随微调任务上进行了评估。
- 微调的有效性在多个基准上进行了评估:MT-Bench包含80个高质量的多轮问题,旨在从多个方面评估LLMs
- MMLU 共包括57个任务,14,079个问题,涵盖了广泛的世界知识;
- AGIEval 是一个以人为中心的通用能力基准,包含9316个实例;
- WinoGrande 是一个用于常识推理的大规模数据集,包含44,000个实例
在我们的实验中,我们评估了3个基线模型:TinyLlama、Mistral-7B 和LLaMA - 2 - 7B 。这些模型的大小从1B到7B不等,提供了仅解码器模型的多样化表示。对于超参数,本节采用LoRA的秩为128,LISA的秩为E + H + 2L。
结果
- 表2
- 基线包括全参数训练( FT )、低秩适应( LoRA ) 和梯度低秩投影( GaLore,Gradient Low-Rank Projection)
- 实验结果表明,LISA在大多数评估轨迹中始终优于其他微调方法,表明了其在不同任务和模型架构下的鲁棒性和有效性。
- LISA在指令跟随任务(instruction following tasks)中特别有效,与其他基线方法相比存在较大差距。
- LISA甚至优于全参数Training,这表明当未冻层的数量受到限制时,存在类似于dropout 的隐式正则化效应。
- 表3
- 根据在稳定扩散和详细MT - Bench分数中的更多结果,我们发现LISA在记忆任务中的表现优于LoRA,例如在图像生成中描绘高分辨率图像细节,或在指令跟踪中的书写或人文任务。
- 这意味着LISA的性能提升可能主要来自于记忆长尾模式的能力,而LoRA更擅长知识有限的多跳推理。
Q:
- table 2里面的几shot是什么意思
- 这几个数据集、测试集、bench是什么,有点混乱
Moderate Scale Continual Pre-training
持续的预训练对于使模型能够适应新的数据和领域至关重要。为了评估LISA在连续预训练场景下的有效性,我们在数学领域进行了实验,并与全参数训练进行了比较。
实验设置
Ettings我们采用数学语料库Open WebMath构建连续的预训练数据集。具体来说,我们从中提取了一个包含15亿个令牌的高质量子集。在连续的预训练之后,我们在GSM8K训练集上应用同样的微调过程,该训练集包含7473个实例。
结果
- table 4 表明LISA能够以更少的内存消耗获得比全参数训练更接近甚至更好的性能。
- 具体来说,与全参数训练相比,LISA只需要一半的内存成本。这表明LISA在计算效率和模型性能之间取得了较好的平衡。
- 根据我们的经验,将未冻结层的数量减少到原始尺寸的一半,在持续的预训练过程中不会导致更差甚至更好的性能,同时需要更少的内存消耗。
Large Scale Fine-Tuning
为了进一步说明LISA在大尺寸LLM上的可扩展性,我们在LLaMA - 2 - 70B 上进行了额外的微调实验。
实验设置
除了4.2节中提到的指令跟踪任务,我们在数学和医学QA基准题上使用了额外的特定领域的微调任务。数学领域使用GSM8K数据集( Cobbe et al , 2021),包含7473个训练实例和1319个测试实例。对于医疗领域,我们选取了PubMedQA数据集,该数据集包括211.3 K人工生成的问答训练实例和1K测试实例。
在PubMedQA数据集上的评估是在5 - shot提示的设置下进行的,而GSM8K数据集( Cobbe et al , 2021)的评估是在最近的研究( Wei et al . , 2022 ; Shum et al , 2023 ; Diao et al , 2023b)之后使用思维链( CoT )提示进行的。关于超参数,如4.1节所述,我们使用LoRA的秩256和LISA的配置E + H + 4L。详细信息见附录B。
结果
Ablation Studiess
LISA的超参数
- LISA的超参数LISA的两个关键超参数是采样层数γ和采样周期K。
- 为了获得这些超参数选择的直观和经验指导,我们利用Alpaca - GPT4数据集,使用TinyLlama和LLaMA - 2 - 7B 模型进行消融研究。
- γ的配置,比如E + H + 2L,E + H + 8L,分别记为γ = 2和γ = 8。
- 对于采样周期K = T / n,T = 122代表我们实验框架中的最大训练步长。
- 如表6所示,结果表明γ和K都显著影响LISA算法的性能。具体来说,较高的γ值增加了可训练参数的数量,尽管内存成本较高。
- 另一方面,一个最优的K值有利于更频繁的层切换,从而将性能提高到一定的阈值,超过这个阈值,性能可能会变差。
- 一般来说,经验法则是:更多的采样层数和更高的采样周期会带来更好的性能。对于损失曲线和MT - Bench结果的详细考察,参见附录A。4
LISA的敏感性
- 由于LISA在算法上依赖于层的采样顺序,因此有趣的是,在随机性的影响下,LISA的性能是如何稳定的。
- 为了达到这个目的,我们进一步研究了LISA在三个不同的运行中的性能差异,每个运行都有一个不同的随机种子用于层选择。
- 在这里,我们采用TinyLlama,LLaMA2 - 7B和Mistral-7B模型,使用Alpaca - GPT4数据集,同时保持所有其他超参数与第4.2节实验中使用的指令保持一致。
- 如表7所示,LISA对不同的随机种子具有很好的适应性,三次运行之间的性能差距在0.13以内,与基线方法相比,性能增益很小。对于更多关于LISA超参数的消融实验,
Discussion
Theoretical Properties of LISA
- 与引入额外参数并导致损失目标变化的LoRA相比,分层重要性采样方法在原始损失中具有良好的收敛性保证。
- 对于逐层重要性采样SGD,类似于梯度稀疏化(gradient sparsification),当方差增大时,梯度的无偏估计仍能保证收敛。
- 通过适当定义重要性采样策略减小方差,可以进一步改善收敛行为。
- 对于逐层重要性采样Adam中的理论结果证明了其在凸目标中的收敛性。
- 如果我们将f表示为损失函数,并且假设随机梯度是有界的,那么基于(洛什奇洛夫和哈特, 2017),我们知道AdamW优化f与带有比例正则项的Adam优化f是一致的,可以写成
- \[f^{\mathrm{reg}}(\mathbf{w})\triangleq f(\mathbf{w})+\frac12\mathbf{w}^\top\mathbf{S}\mathbf{w},\]
- 式中:S为有限半正定对角矩阵。沿用RBCAdam (Corollary1)已有的收敛结果,我们有Theorem 1.中LISA的收敛性保证。
Theorem 1
设损失函数f是凸且光滑的.如果算法运行在一个有界凸集上,且随机梯度是有界的,则由LISA生成的序列\({ w_t } ^T_{t=1}\)有如下的收敛速度:
\[\frac1T\sum_{t=1}^Tf^{\mathrm{reg}}(\mathbf{w}_t)-f_*^{\mathrm{reg}}\leq O\left(\frac1{\sqrt{T}}\right),\]
式中:\(f ^{reg}_ *\)表示f ^reg的最优值。
Memorization and Reasoning
在附录A.1和A.2的教学实验中,我们观察到LISA在以记忆为中心的任务(如书写或描绘图像细节)上明显优于LoRA,而在以推理为中心的任务(如代码或数学)上,这种差距要小得多。这是一个有趣的观察,因为LISA更注重层宽,限制了学习参数的深度,而LoRA更注重深度,限制了每层的表示空间。这可能表明宽度对于记忆是至关重要的,而深度对于推理是重要的,类似的现象与( Cheng et al . , 2016)的直觉相呼应。基于同样的直觉,或许可以将两者的优点结合起来,提出更好的PEFT方法。
conclusion
在本文中,我们提出了逐层法Importance Sampled AdamW ( LISA ),一种基于给定概率随机冻结LLM层的优化算法。受LoRA的偏态权重范数分布的启发,提出了一种简单的存储高效冻结范式用于LLM训练。该范式在包括LLaMA - 2 - 70B在内的多种模型的下游微调任务上取得了比LoRA显著的性能提升。针对特定领域训练的进一步实验也证明了其有效性,显示了LISA作为LLM训练的LoRA的有前途的替代方法的巨大潜力。
Limitations
LISA的主要瓶颈与LoRA相同,在优化过程中,前向传递仍然需要将模型呈现在内存中,导致显著的内存消耗。这种限制将通过类似于QLoRA (德特默斯等, 2023)的方法来弥补,我们打算进行进一步的实验来验证其性能。此外,根据理论直觉,4.2节中的E + H + 2L和4.4节中的E + H + 4L策略可能不是最优的重要性采样策略,因为它仍然以均匀随机的方式对中间层进行采样。我们预计,在重要性采样过程中,当考虑数据源和模型结构时,优化器的效率将进一步提高。
code
根据github上issue的解答,lisa的主要运行模块是src.py里面
- freeze,没想到冻结居然就是设置requires_grad为false
1
2
3
4
5def freeze_all_layers(self):
layers = eval('self.' + self.layers_attribute) # Dynamically execute to get layers
for layer in layers:
for param in layer.parameters():
param.requires_grad = False
个人总结
每章重点
abstract
- lora比不过全参,因为参数搜索只在low rank子空间里面。
- 做实验观察lora逐层,发现weight norm的规律。
- 提出lisa,比lora和全参效果都好,内存消耗和lora一样。给LLMs每层上重要性采样,在优化时随机冻结大部分中间层。
introduction
研究lora在每一层的训练统计量,发现逐层权重规范不同,应用重要性采样的思想
related works
这章是讲相关工作的,以此包括:LLM(研究领域),PEFT方法(但是它不是只改了lora吗),lora(依葫芦画瓢的葫芦),大规模优化算法(搞优化的,反正最后作者还是用adamw了)
methods
- 测算mean-weight-norm,发现结论
- 根据结论设计lisa的算法
motivation
做了对比试验计算mean-weight-norms of each layer,得到的结果是lora的话会在嵌入层或者LM的头层获得更高的weight-norm,全参数微调就没有这种效果。结论:LoRA和全参数训练的更新侧重点存在显著差异,从而想到分层。
LISA
提出了一个算法LISA,用学习率来模拟lora并控制顶层和底层freeze